Why PostgreSQL Should Be Your Database Default (And Why Everything Else Is Just Marketing)
Most startups pick the wrong database and pay for it. After a 10-hour outage on YugabyteDB, Cursor switched to PostgreSQL on AWS RDS. It just worked. Reliable, scalable, and lock-in free PostgreSQL quietly powers the internet without the hype or headaches.
The Cursor guys had it figured out all along—until they didn't.
You're scaling to 100 million inference calls daily, your database is melting under a 22-terabyte workload, and AWS RDS architects are literally telling you "gosh, you guys are in big trouble" while offering zero solutions. That's exactly what happened to Cursor's engineering team when they tried to get clever with YugabyteDB.
The punchline? After a catastrophic 10-hour incident that nearly killed their indexing system, they moved the workload to plain old PostgreSQL on RDS. Result: "It works like a charm."
Here's the uncomfortable truth: Your shiny new database choice is probably wrong.
The Database Complexity Trap
![[Comic strip: Panel 1 shows excited stick figure developer with sparkly eyes looking at a complex flowchart labeled "Distributed Consensus Protocol". Panel 2 shows the same figure 6 months later, disheveled, debugging at night while users can't log in. Panel 3 shows PostgreSQL elephant mascot saying "Still here when you're ready."]](https://bytes.vadeai.com/content/images/2025/07/oostgres-database.png)
I've watched brilliant engineers make the same mistake over and over. They start a new project, get excited about some distributed system they read about in a Google paper, and decide PostgreSQL is "too boring" for their revolutionary idea.
Six months later, they're debugging Byzantine consensus protocols at 3 AM while their users can't log in.
The problem isn't that these other databases are inherently bad—it's that they solve problems you probably don't have, while creating problems you definitely didn't want.
Why PostgreSQL Wins By Being Boring
![[Stick figure comparison: On left, a flashy sports car (labeled "NoSQL") broken down on the roadside with steam coming out, driver looking frustrated. On right, a reliable sedan (labeled "PostgreSQL") cruising smoothly past with a happy driver giving thumbs up.]](https://bytes.vadeai.com/content/images/2025/07/oostgres-database-1.png)
PostgreSQL is the Toyota Camry of databases. Not sexy, not trendy, but it starts every morning and gets you where you need to go. Here's why that matters more than you think:
1. It Actually Works at Scale
Cursor processes billions of documents daily on PostgreSQL. Instagram scaled to hundreds of millions of users on PostgreSQL. GitHub's entire platform runs on PostgreSQL. These aren't toy problems—these are real systems serving real users.
2. Zero Vendor Lock-in
Every major cloud provider offers managed PostgreSQL. You can run it on-premises. You can switch providers without rewriting your application. Try doing that with DynamoDB or any other proprietary system.
3. The Ecosystem is Massive
Need full-text search? PostgreSQL has it built-in. Want JSON documents? Native support. Vector operations for AI workloads? pgvector has you covered. Time-series data? TimescaleDB extension. The tooling, monitoring, and expertise exists everywhere.
4. SQL is Your Friend
I know it's not fashionable to say this, but SQL is actually good. It's declarative, it's optimizable, and it's been battle-tested for decades. When you need to answer "how many users signed up last month," you write a 30-second query instead of spinning up an ETL pipeline.
The Vendor Marketing Machine: A Field Guide to Database Snake Oil
![[Carnival barker stick figure in top hat shouting through megaphone: "Step right up! Get your serverless, AI-native, web-scale database solutions here!" Confused developers holding money looking skeptical]](https://bytes.vadeai.com/content/images/2025/07/oostgres-database-2.png)
Let me be blunt about something: most database startups exist to solve problems they created.
Walk through any tech conference today and you'll be bombarded by database vendors promising to revolutionize your data stack. The pattern is always the same: create artificial complexity, then sell you the solution. Here's your exhaustive guide to the database marketing circus:
The "Serverless" Gold Rush
![[Gold rush scene with stick figures panning for gold, but instead of gold nuggets, they're finding "serverless" buzzwords. One figure holds up a sign: "PostgreSQL with auto-scaling - $$"]](https://bytes.vadeai.com/content/images/2025/07/oostgres-database-4.png)
NeonDB just raised $104M to give you "serverless PostgreSQL." Sounds great until you realize you're paying premium pricing for... PostgreSQL with auto-scaling. PlanetScale burned through millions promising "serverless MySQL" before quietly killing their free tier when the unit economics didn't work. Turso wants you to believe SQLite needs to be "at the edge" for reasons that remain unclear.
Supabase markets itself as the "open source Firebase alternative" but locks you into their hosting platform. FaunaDB promises "serverless, globally distributed" everything while making simple queries feel like rocket science.
The AI Vector Database Goldmine
The AI hype created an entire category of expensive solutions looking for problems:
Pinecone raised $138M to store vectors that PostgreSQL with pgvector handles just fine. Weaviate, Chroma, Qdrant, and Milvus are all fighting for chunks of a market that mostly doesn't need specialized vector databases.
The dirty truth? Unless you're building the next Google Search, PostgreSQL's vector support probably handles your AI workload better than these specialized tools that cost 10x more.
The NoSQL Identity Crisis
MongoDB still pushes "flexibility" while most users spend their time fighting its query limitations. DataStax rebranded Cassandra as "serverless" because even they know nobody wants to operate Cassandra clusters. ArangoDB promises to be your graph, document, and key-value database all in one—a sure sign it's not great at any of them.
The Time-Series Trap
InfluxDB convinced half the monitoring world they needed a specialized time-series database. Most of these companies are now quietly migrating back to PostgreSQL with TimescaleDB because, surprise, relational data benefits from relational queries.
The Analytics Upsell
Snowflake and Databricks have entire sales teams dedicated to convincing you that your PostgreSQL analytics aren't "enterprise-ready." ClickHouse promises blazing speed while requiring you to learn yet another query language.
The Graph Database Mirage
Neo4j has spent a decade trying to convince developers they need graph databases for basic relationship queries. Most "graph" problems are solved better with PostgreSQL's recursive CTEs and JSON operations.
The Acquisition Frenzy: Follow the Money
![[Monopoly board with stick figures as game pieces being absorbed by larger corporate buildings. Dollar signs flying around as smaller database startups get gobbled up by bigger platforms]](https://bytes.vadeai.com/content/images/2025/07/ChatGPT-Image-Jul-27--2025--09_54_31-PM.png)
Here's what really tells you everything about the database market: the acquisition pattern. Look at who's buying whom and why:
- Confluent acquired WarpStream for $23M to solve Kafka's operational nightmare
- Databricks keeps acquiring smaller analytics companies to patch gaps in their platform
- Snowflake spent billions buying Streamlit and others to create vendor lock-in
Notice the pattern? These companies aren't solving user problems—they're solving their own growth problems by eliminating competition and increasing switching costs.
The NeonDB Case Study: When Marketing Meets Reality
![[Stick figure startup founders celebrating with "$1B EXIT!" banner, while confused customers in background ask "Wait, what happens to our databases now?" Databricks figure in suit says "Trust us, everything will be fine."]](https://bytes.vadeai.com/content/images/2025/08/image.png)
NeonDB perfectly illustrates the database startup playbook in action. Founded in 2021, they raised $129.6 million selling "serverless PostgreSQL" to solve problems that AWS RDS Aurora already handled. Four years later, in May 2025, Databricks acquired them for approximately $1 billion.
On paper, that's a massive success. But here's what it really represents: a billion-dollar bet that developers needed a specialized PostgreSQL wrapper instead of just using... PostgreSQL. Databricks cited that "over 80 percent of the databases provisioned on Neon were created automatically by AI agents rather than by humans" as a key selling point.
The uncomfortable question for Neon's 18,000+ customers: What happens when your database vendor becomes a feature inside someone else's platform? Databricks plans to "continue innovating and investing in Neon's database and developer experience for existing and new Neon customers" – but we've heard that song before from every acquirer.
The Vendor-First Reality
![[Flowchart showing vendor decision tree: "Will this increase our ARR?" → YES → "Ship it!" → NO → "Marketing will figure it out." User needs shown as tiny afterthought in corner]](https://bytes.vadeai.com/content/images/2025/07/oostgres-database-5.png)
Here's the uncomfortable truth: database vendors optimize for their revenue, not your success.
Every feature decision, every pricing tier, every "enterprise" upsell is designed to maximize their ARR (Annual Recurring Revenue), not minimize your operational overhead. They want you dependent on their platform, locked into their ecosystem, and paying increasing bills as you scale.
Consider the classic vendor playbook:
- Hook: Generous free tier or "developer-friendly" pricing
- Growth: Easy initial setup, lots of marketing content
- Lock-in: Proprietary features that make migration painful
- Extract: Sudden pricing changes, feature restrictions, or acquisition by larger vendor
PostgreSQL breaks this cycle completely. No vendor owns it. No startup can kill it. No acquisition can change your pricing overnight. It's boring infrastructure that just works.
The dirty secret? PostgreSQL probably scales further than your startup ever will.
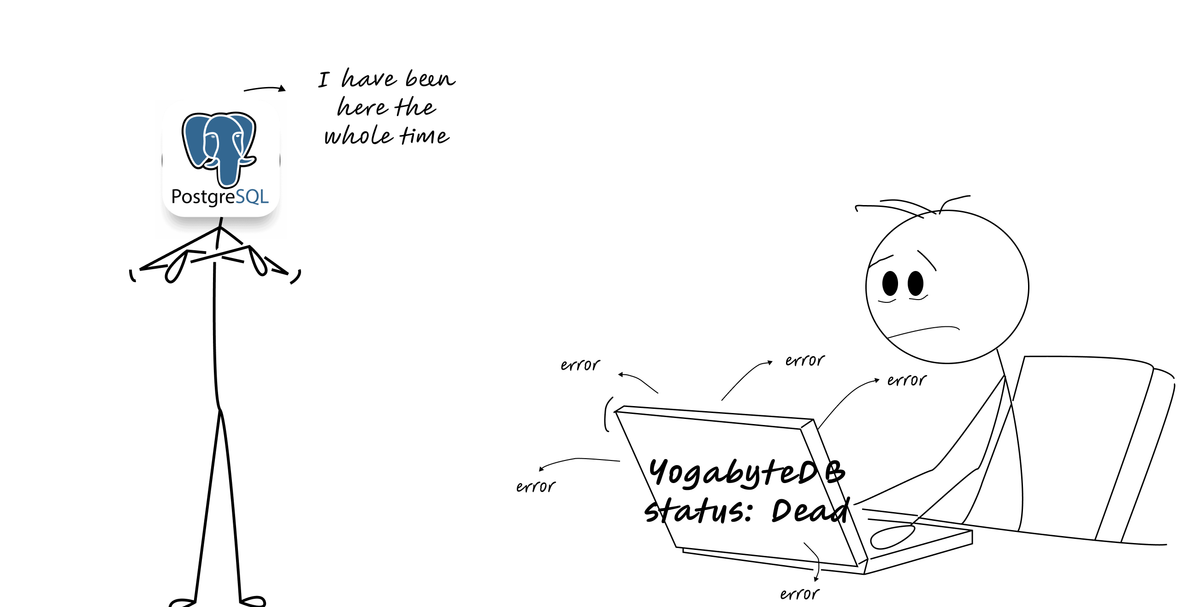
Real-World War Stories
![[Stick figure engineer drowning in complexity diagrams labeled "Consensus Protocol" while simple PostgreSQL solution sits unused on the shelf with a note: "I was here all along"]](https://bytes.vadeai.com/content/images/2025/07/ChatGPT_Image_Jul_27__2025__10_18_44_PM-removebg-preview--1-.png)
The YugabyteDB Incident
Cursor's team thought they were being smart. YugabyteDB promised infinite scale with PostgreSQL compatibility. What they got was a database that "just wouldn't run" despite paying substantial money and scaling down as much as possible.
The lesson? Compatibility isn't the same as reliability. Moving to actual PostgreSQL on RDS solved their problems instantly.
The MongoDB Trap
I've seen too many fresh graduates start projects with MongoDB because it felt "modern." Three months in, they're trying to implement joins across collections and wondering why their queries take forever. The answer is always the same: MongoDB isn't a relational database, and trying to use it like one is architectural malpractice.
The DynamoDB Pivot
One startup I consulted for spent eight months building their product on DynamoDB. Their access patterns worked great—until they needed analytics. Suddenly, "how many premium users do we have?" required a full table scan of millions of records. They ended up building a complex ETL pipeline to dump data into... PostgreSQL.
When Alternatives Actually Make Sense
I'm not completely dogmatic here. There are legitimate use cases for other databases:
Elasticsearch if search is literally your core product feature. But honestly, PostgreSQL's full-text search handles 90% of use cases just fine.
Redis for caching and session storage. But remember, it's a cache, not your primary database.
Kafka if you're doing real event streaming across multiple teams. But again, a PostgreSQL table works perfectly as an append-only log until you're processing terabytes.
Specialized time-series databases if you're literally building monitoring infrastructure. But check out TimescaleDB first.
The pattern here? Use specialized tools when the specialization actually matters to your core business.
The RDS Reality Check
Here's something nobody talks about: managed PostgreSQL is stupidly good. AWS RDS, Google Cloud SQL, Azure Database—they've solved the operational complexity that used to make database administration a nightmare.
Automated backups? Check. Read replicas? Check. Security patches? Check. High availability? Check. Performance monitoring? Check.
You get all the benefits of PostgreSQL without becoming a database administrator. That's not vendor lock-in—that's strategic delegation.
The Bottom Line
Start with PostgreSQL. Scale with PostgreSQL. When you actually hit its limits, you'll know exactly what those limits are and what you need instead.
Most projects never reach those limits. The ones that do usually have very specific requirements that make the trade-offs obvious.
Stop trying to predict your scaling problems and solve the problems you actually have. PostgreSQL on a managed service like RDS will handle more load than you think, with less operational overhead than you expect, and fewer architectural regrets than any alternative.
Your future self—the one debugging database issues at 2 AM—will thank you for choosing boring reliability over sexy complexity.
Save the innovation budget for the parts of your system that actually differentiate your product. Your database should be invisible infrastructure that just works, not an exciting technical challenge that breaks at the worst possible moment.
Trust me on this one. I've debugged enough exotic database incidents to know that boring wins.