The Research That Explains Why Your LLM Keeps Messing Up
Ever noticed your AI gets worse the longer you chat? Groundbreaking research shows even top LLMs lose the plot in multi-turn conversations—causing reliability issues and inconsistent results. Learn what’s behind this, and how tools like Vade AI are adapting.

You know that feeling when you're working with an LLM and it starts off brilliantly, but by the end of your conversation, it's producing complete nonsense? Well, turns out I'm not going crazy, and neither are you. A fascinating new research paper from Microsoft and Salesforce has finally put numbers to what many of us have been experiencing: LLMs literally get lost in multi-turn conversations.
The 'Aha' Moment with Vade AI

Let me tell you why this research hit home for me. At Vade AI, we're building a no-code platform for creating multilingual websites. I've been watching our LLM integrations like a hawk, and I kept noticing this weird pattern. The AI would start by creating gorgeous, pixel-perfect UI components that followed our design system beautifully. Header sections? Absolutely stunning. Navigation menus? Chef's kiss.
But then something bizarre would happen. As the conversation progressed and we asked for more sections, the quality would just... deteriorate. The footer would look like it belonged on a completely different website. Colors would be off. Spacing would be inconsistent. It was like watching a skilled designer slowly lose their mind.
I thought maybe it was our prompts or our system. Turns out, it's actually a fundamental limitation of how current LLMs handle extended conversations.
The Research
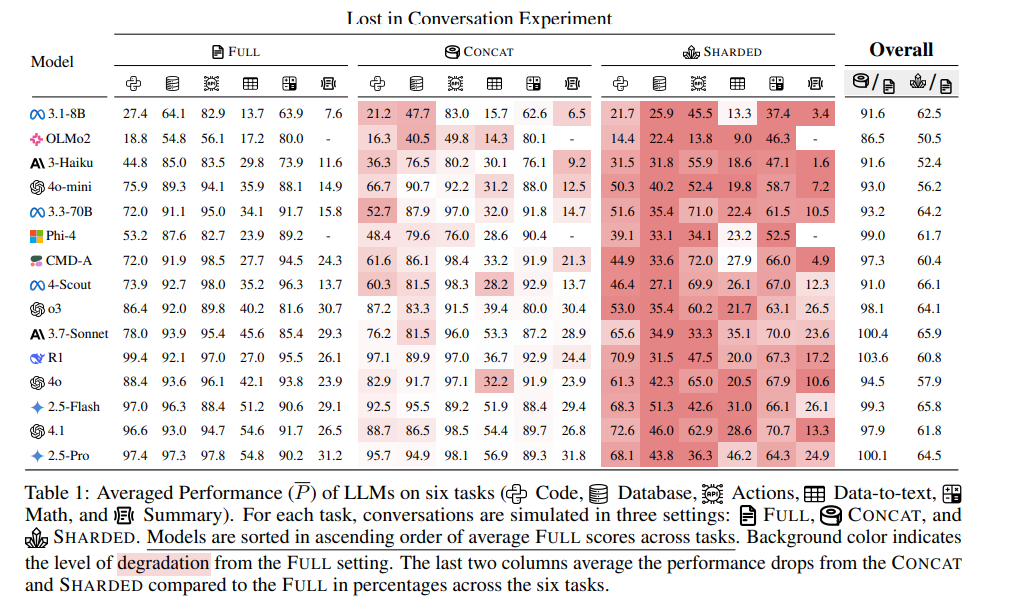
The Microsoft-Salesforce team ran an experiment testing 15 different LLMs across six different tasks. They compared how models performed when given complete instructions upfront versus when information was revealed gradually across multiple turns (you know, like how real conversations actually work).
The results? Absolutely devastating. Every single model they tested showed significant performance drops in multi-turn settings, with an average degradation of 39%. We're talking about models like GPT-4, Claude, and Gemini - the cream of the crop - all struggling with the same fundamental issue.
The "Sharding" Experiment
The researchers created what they call "sharded instructions." They took single, complete prompts and broke them into smaller pieces of information that would be revealed turn by turn. Think of it like this: instead of saying "Build me a red car with leather seats and a sunroof," they'd start with "Build me a car," then add "Make it red," then "Add leather seats," and finally "Include a sunroof."
What they found was mind-blowing. The same LLM that could nail the task when given all information at once would completely botch it when the same information was spread across multiple turns. And this happened even when the total information was identical!
Why This Happens: The Psychology of Lost AI
The research identified four key behaviors that explain why LLMs get lost:
1. Premature Answer Attempts LLMs are like that eager student who raises their hand before hearing the full question. They start generating solutions before they have all the context, leading to incorrect assumptions that poison the entire conversation.
2. Answer Bloat As conversations progress, LLM responses get longer and more convoluted. It's like they're trying to incorporate every previous attempt instead of starting fresh. The researchers found that final answers in multi-turn conversations were 20-300% longer than their single-turn equivalents!
3. Loss of Middle Context LLMs pay most attention to the first and last parts of a conversation, often forgetting crucial information shared in the middle. Sound familiar? It's like the AI equivalent of walking into a kitchen and forgetting why you came there.
4. Verbal Diarrhea Longer responses typically contain more assumptions and hypotheses, which create more opportunities for confusion in subsequent turns.
The Reliability Crisis
The research shows that the performance drop isn't just about LLMs becoming less capable (though that happens too). The bigger issue is that they become wildly unreliable. The same prompt that works perfectly in one conversation might fail completely in another, even with identical context.
The researchers measured this by running the same conversations multiple times and found that while single-turn interactions were relatively consistent, multi-turn conversations had massive variation in quality. It's like having a brilliant chef who can make a perfect dish when given the full recipe but burns everything when you give them ingredients one by one.
What This Means for Real-World Applications
This research validates something I've been experiencing firsthand with Vade AI. When we generate website sections one by one, the AI loses track of the overall design vision. That beautiful header it created? By the time we get to the footer, it's forgotten the color scheme, the typography choices, and the brand guidelines we established earlier.
It explains why so many AI applications feel inconsistent and why users often restart conversations when things go wrong. We're not being impatient; we're unconsciously working around a fundamental limitation of current LLM architecture.
The Temperature Red Herring
One fascinating finding: turning down the "temperature" (randomness) of LLMs doesn't fix the multi-turn reliability problem. Even at the most deterministic settings, the models still get lost in conversation. This suggests the issue goes deeper than just randomness in text generation.
Practical Solutions (For Now)
While we wait for better models, the research suggests a few practical approaches:
1. Consolidate Before Retrying If a conversation goes off track, ask the LLM to summarize everything discussed so far, then start a new conversation with that consolidated context.
2. Minimize Turn Count Provide as much context as possible upfront rather than revealing information gradually.
3. Reset Early and Often Don't be afraid to start fresh when you notice quality degrading. It's not your fault; it's a limitation of current technology.
4. Use Agent-Like Approaches Carefully The research shows that techniques like recapping previous turns can help, but only modestly. They're Band-Aids, not cures.
The Path Forward
This research is a wake-up call for the AI community. We've been so focused on making models smarter in single interactions that we've overlooked how they handle the conversational nature of real-world use.
For builders like me working on platforms like Vade AI, this research validates our experiences and gives us a roadmap for better solutions. We're already experimenting with conversation management techniques and context consolidation strategies.
The good news? Now that we understand the problem, we can start building better solutions. The researchers explicitly call on LLM builders to prioritize multi-turn reliability alongside raw capability.
The Bottom Line

If you've ever felt like AI gets dumber the longer you talk to it, you're not imagining things. This research proves it's a real, measurable phenomenon affecting all current LLMs. But knowing is half the battle.
As we build the next generation of AI-powered tools, this research gives us the framework to create more reliable, conversation-aware systems. The future of AI isn't just about smarter models; it's about models that can maintain context and quality across extended interactions.
Until then, we adapt, we work around the limitations, and we build solutions that account for the reality of how LLMs actually behave in the wild. Because sometimes, the most important research isn't about making things work better—it's about understanding why they don't work as well as we thought they did.