The Illusion of Thinking: What Happens When AI "Overthinks"
AI “thinking” modes promise smarter results, but do they deliver? Explore new research revealing when extra reasoning helps—and when it leads to failure, early answer fixation, and surprising limitations in complex problem-solving.
TL;DR
- Regular models beat thinking models on simple tasks—faster and more accurate
- Thinking models excel at medium-complexity problems where reasoning helps
- Both model types collapse completely on high-complexity tasks
- Counterintuitive behavior: Thinking models reduce reasoning effort as problems get harder
- Early answer fixation: Models stick to wrong initial solutions and waste thinking budget
- Poor generalization: Success on one puzzle type doesn't transfer to similar tasks
- Bottom line: That spinning "thinking" indicator doesn't guarantee better results
Imagine, you're sitting in front of your computer, watching Claude or O1 furiously "think" through a problem for what feels like an eternity, generating thousands of tokens of internal reasoning. The little thinking indicator spins, you wait expectantly, and then... the model completely bombs a problem that seemed well within its capabilities. Sound familiar?
I've been there countless times. Just last week, I asked Claude (with thinking mode on) to help me design a creative landing page for a new project. The response was technically perfect—every design principle followed to the letter, every accessibility guideline checked off—but it was absolutely soulless. The moment I switched off thinking mode and asked the same question, I got this wonderfully unexpected design with bold color choices and creative layouts that I never would have thought of myself.
This personal experience made me incredibly excited when I stumbled across a fascinating new research paper from Apple that dives deep into exactly this phenomenon. The researchers asked a deceptively simple question: Are these "reasoning" models actually better at reasoning, or are we just being fooled by all that internal chatter?
The Reasoning Experiment
The Apple team did something interesting. Instead of testing these Large Reasoning Models (LRMs) like O1, Claude Thinking, and DeepSeek-R1 on the usual math benchmarks that everyone uses, they created controlled puzzle environments. Think Tower of Hanoi, but with the ability to precisely dial up the complexity and peek inside the model's "thoughts" as it works.
Why puzzles instead of math problems? Well, here's the thing about those standard benchmarks—they're probably contaminated. These models have likely seen variations of MATH-500 problems during training. But a Tower of Hanoi puzzle with 15 disks? That's algorithmically pure and uncontaminated.
The results were eye-opening. The researchers discovered three distinct "reasoning regimes" that perfectly mirror my own experiences:
The Three Faces of AI Reasoning
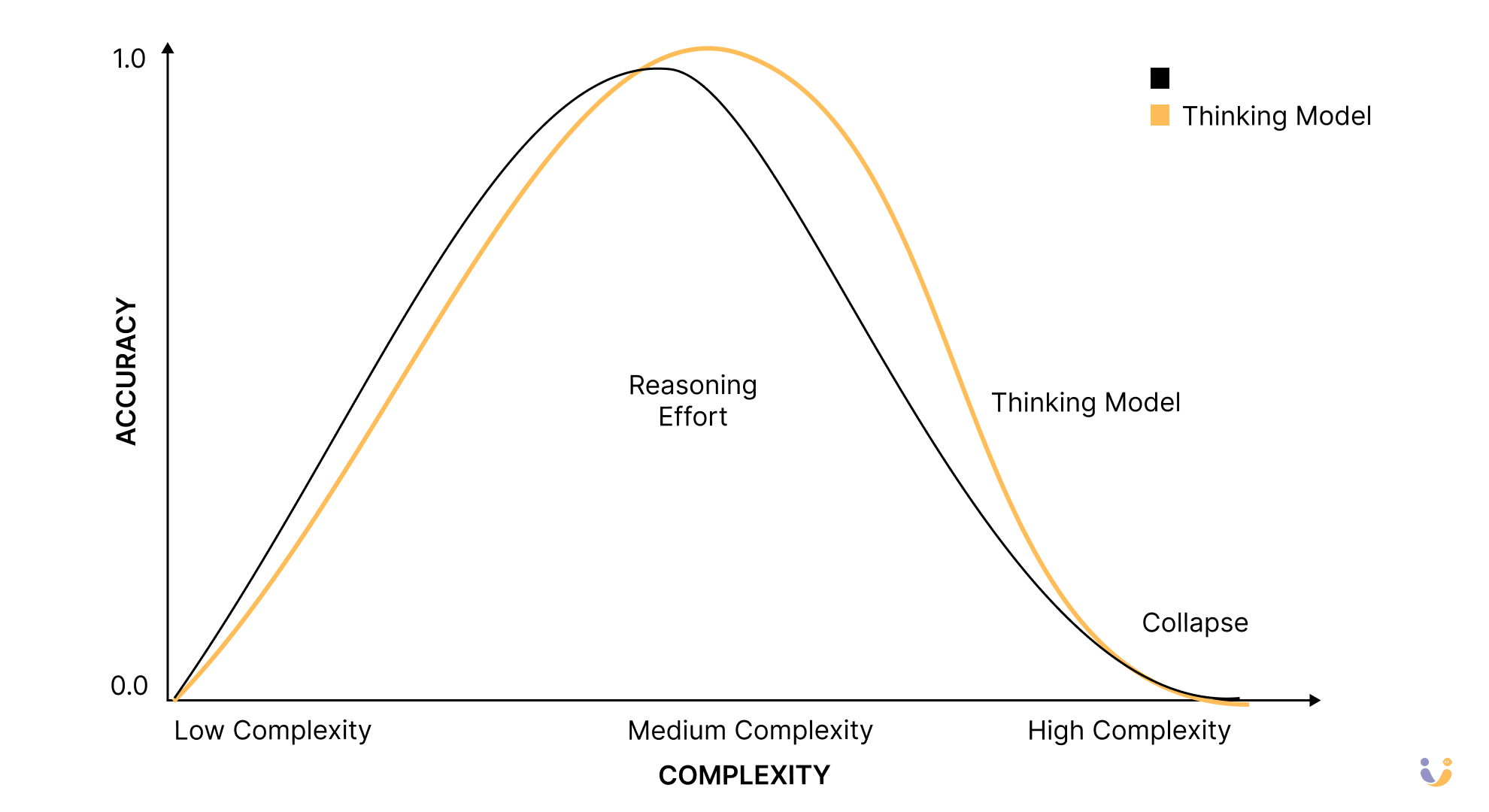
01: The Overthinking Zone (Low Complexity) For simple problems, standard models without thinking actually outperformed their reasoning counterparts. This blew my mind initially, but it makes perfect sense when I think about my creative work experiences. When I need Claude to write a punchy headline or come up with an unexpected twist for a story, thinking mode often produces something that feels like it was written by a committee.
The researchers found that reasoning models often find the correct solution early but then keep exploring incorrect alternatives. It's like having a friend who figures out the right answer in the first 30 seconds but then spends an hour second-guessing themselves into oblivion.
02: The Sweet Spot (Medium Complexity) Here's where thinking models shine. Moderately complex logical problems, multi-step reasoning, algorithmic challenges—this is their domain. When I need Claude to help me debug a tricky Clojure function or work through a decently complex data transformation, thinking mode is absolutely golden. The extra reasoning pays off.
03: The Collapse (High Complexity) But here's where it gets really interesting. Beyond a certain complexity threshold, both thinking and non-thinking models just... collapse. Complete failure. Zero accuracy. It's like watching a Formula 1 car suddenly forget how to drive.
The Counterintuitive Discovery
The most shocking finding? As problems get harder, thinking models actually start thinking less. You'd expect them to use more tokens, more reasoning, more internal processing. But no—they hit a wall and give up, using fewer thinking tokens despite having plenty of computational budget left.
It's like watching someone encounter a difficult crossword puzzle and instead of working harder, they just... put the pen down. The researchers call this a "fundamental scaling limitation" and honestly, it's kind of terrifying from an AI capabilities perspective.
Looking Under the Hood
The researchers didn't just measure final answers—they actually analyzed the intermediate solutions that appear in the models' thinking traces. This is where things get really fascinating.
For simple problems, models often nail the solution early but then waste the rest of their thinking budget exploring wrong paths. For moderately complex problems, they struggle through many incorrect attempts before finding the right answer near the end. And for complex problems? They never find correct solutions at all.
This explains so much about my experience! When I ask for creative output, the first instinct is often the best one, but thinking mode forces the model to overthink it into mediocrity. When I need logical, step-by-step work, that extensive exploration and self-correction is exactly what I want.
The Algorithm Surprise
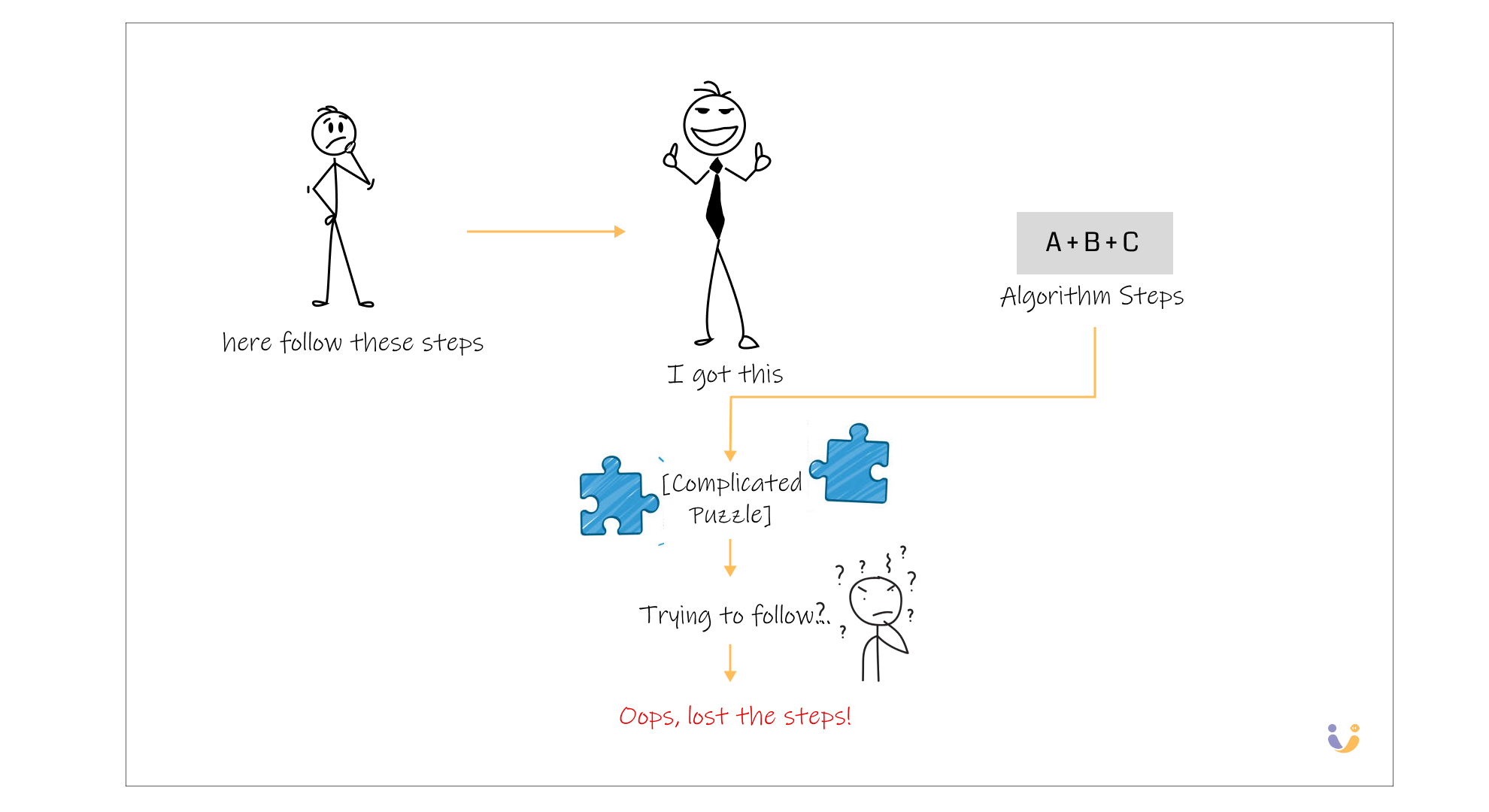
Here's something that really surprised me: even when the researchers gave the models the exact algorithm to solve Tower of Hanoi—literally just "follow these steps"—the models still failed at the same complexity levels. This isn't about not knowing how to solve the problem; it's about fundamental limitations in following logical steps consistently.
This finding has huge implications. It suggests that current reasoning models have genuine difficulties with symbolic manipulation and exact computation, not just with problem-solving strategies.
What This Means for Real-World Use
This research validates something I've been noticing in my daily AI use. Thinking models aren't universally better—they're specialized tools. For creative work where you want surprising, varied output, traditional models often excel. For logical, step-by-step reasoning where consistency matters, thinking models are your friend. But for extremely complex problems? Well, we're all still waiting for that breakthrough.
The researchers also found that reasoning models show much higher variance in their failure patterns. They might succeed brilliantly on one complex problem and fail spectacularly on a similar one. This inconsistency is something I've definitely experienced—some days Claude's reasoning feels superhuman, other days it makes basic logical errors.
The Bigger Picture
What excites me most about this research is how it challenges the current AI hype cycle. We're constantly told that more reasoning tokens equals better performance, but this study shows that's not always true. Sometimes less is more.
The findings also suggest that the path to better AI reasoning isn't just about scaling up thinking time or model size. We need fundamental breakthroughs in how these models handle symbolic reasoning, maintain consistency across problem scales, and allocate their computational resources.
For those of us using these tools daily, the takeaway is clear: understand the regimes. Use thinking mode for complex logical tasks, switch it off for creative work, and remember that even the most sophisticated reasoning models have hard limits. The key is knowing when you're approaching those limits and adjusting your approach accordingly.
The illusion of thinking is real—sometimes that spinning indicator is just a model spinning its wheels. But understanding when and why these models work best? That's the real intelligence multiplier.