How Transducers Saved Our LLM Processing Pipeline
Ever wrestled with laggy LLM streams and memory spikes? We did—until transducers swooped in. Here’s how they turbocharged our Clojure pipeline and saved our sanity (and sleep).

If you've spent any time in the Clojure ecosystem, you've probably heard whispers of transducers.
Maybe you nodded along, pretending to understand while secretly thinking, "What the hell is a transducer and why should I care?"
I'm going to tell you why you should not just care, but fall in love with them, especially if you're processing streaming data from LLMs.
The Breaking Point
Picture this: it's 11 PM, I've just put my 8-month-old to bed after hours of fussing, and now my phone won't stop buzzing with alerts. Instead of doing some real work before I get some sleep, I'm staring at error messages and CPU graphs that look like the heart rate monitor of someone having a panic attack.
I'm elbow-deep in log files, while our LLM processing pipeline is falling apart.
We're streaming Server-Sent Events (SSE) from 3 different LLM providers, parsing each chunk, and trying to build coherent responses in real-time. The application is choking on memory and introducing latency that makes our real-time UI generation about as "real-time" as sending a letter by carrier pigeons.
I wasn't just tired – I was pissed. We were handling streams from OpenAI, Anthropic, and Google's Gemini with code that looked something like this:
(defn parse-sse-event [line]
(when-not (str/blank? line)
(when (str/starts-with? line "data: ")
(let [data (str/replace line #"^data: " "")]
(when-not (= data "[DONE]")
(try (json/decode data)
(catch Exception _ nil)))))))
(defn process-llm-stream [stream]
(->> (line-seq stream)
(map parse-sse-event)
(filter identity)
(map parse-stream-chunk)
(map enrich-with-metadata)
(into [])))Clean, readable, and absolutely killing our performance. Let me tell you exactly what was happening:
- Each SSE event line from the API comes in as a string
- We parse it, extract the JSON, decode it
- Filter out nulls and empty responses
- Transform the chunks
- Put it all into a vector
For every step in this pipeline, Clojure was creating an intermediate lazy sequence. When you're receiving thousands of token chunks per second across multiple concurrent sessions, these intermediate sequences quickly become memory bombs waiting to explode.
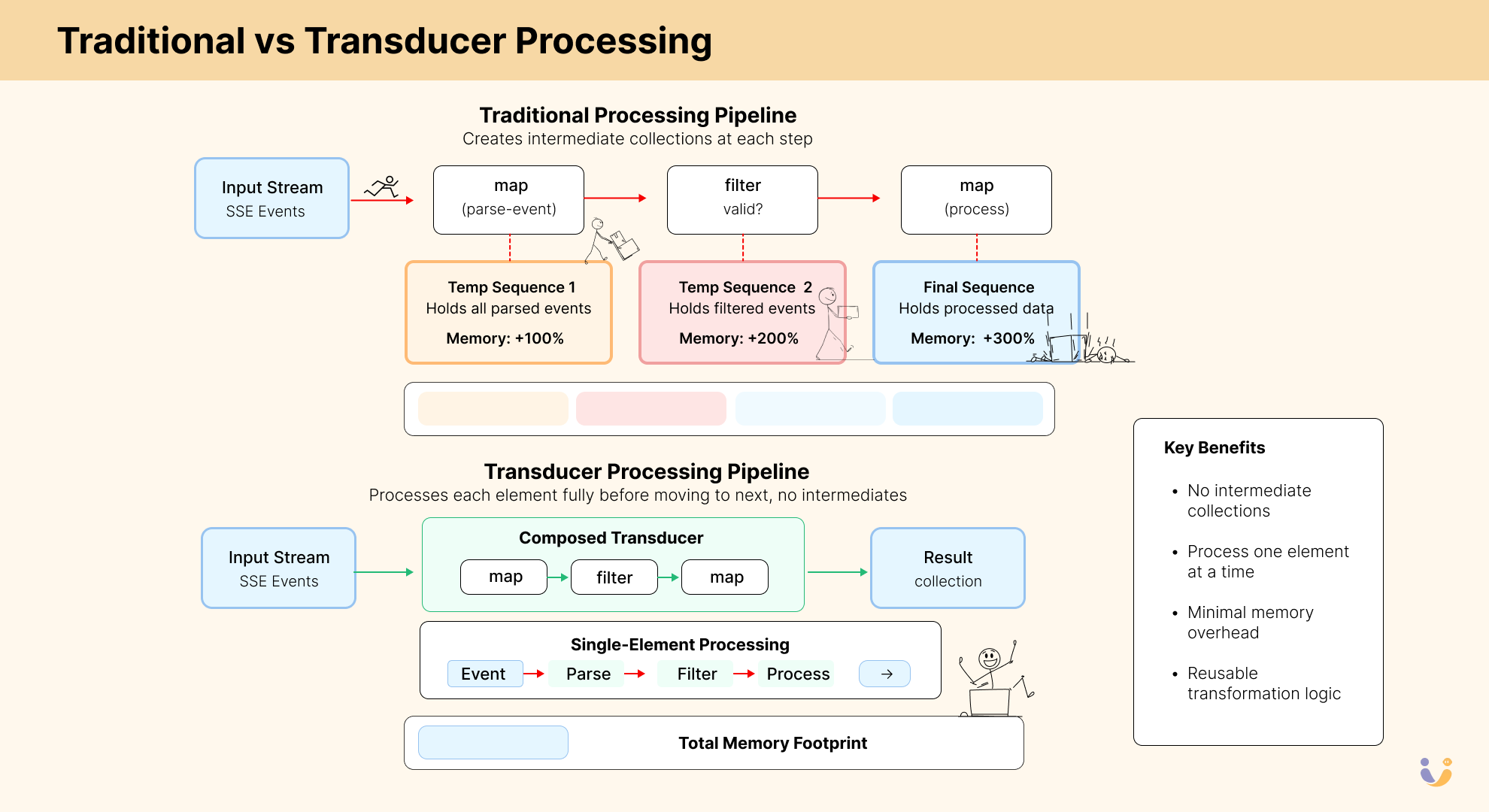
The Real SSE Processing Bottlenecks
Let me break down what was actually choking our system:
- Memory Pressure: Each intermediate sequence held every token from the stream. With multiple transformations, we were essentially creating multiple copies of the same data. When processing 100000+ tokens per minute across multiple concurrent users, this quickly becomes untenable.
- Chunked Sequence Realization: When processing lazy sequences, Clojure uses a chunking strategy. By default, Clojure processes sequences in chunks of 32 elements, at a time, for performance reasons. This chunking behavior is implemented in
ChunkedConsand related classes in the Clojure core. This means that even if you only need the first element, Clojure will realize and process at least 32 elements. When filtering streams, this leads to wasted computation on elements that might be discarded. - Garbage Collection Hell: All those intermediate sequences needed to be garbage collected. When your GC is running constantly, your entire application feels like it's wading through mud.
- Eager Evaluation Needs: We often needed to process streams in real-time for things like content moderation or sentiment analysis. But forcing lazy sequences defeats their main benefit.
This is when I remembered something Rich Hickey mentioned in a talk years ago – the strange alchemy of transducers.
What Transducers Actually Are
Let's cut through the academic jargon. At their core, transducers are composable algorithmic transformations decoupled from their input and output sources.
If your eyes just glazed over, let me translate: transducers let you define how to process each element once, then apply that processing to anything – collections, channels, or streams – without creating wasteful intermediate collections.
Think of transducers as transformation recipes rather than the act of cooking itself. The recipe doesn't care if you're making one serving or feeding an army – it just defines what to do with each ingredient.
In Clojure terms, a transducer is a function that takes a reducing function and returns another reducing function. That's the formal definition, but it misses the f*cking point entirely.
The point is this: transducers let you manipulate data with zero overhead as it flows through your system.
Here's what our SSE processing code looks like with transducers:
(defn- parse-sse-event
"Parse a server-sent event"
[line]
(when-not (str/blank? line)
(when (str/starts-with? line "data: ")
(let [data (str/replace line #"^data: " "")]
(when-not (= data "[DONE]")
(try (json/decode data)
(catch Exception _ nil)))))))
(defn generate-stream [this messages {:keys [as] :as opts}]
(trace! {:id :llm/generate-stream
:otel/span-kind :client
:otel/trace-attrs {:llm/model-id (:id config)
:llm/provider (:provider config)
:llm/message-count (count messages)}}
(let [url (build-url config :stream)
req-body (format-request this messages opts)
{:keys [body request-time]} (http/post url (json/encode req-body)
{:content-type :json :as :stream})
fold-fn (or as fold/default)
xform (comp
(map parse-sse-event)
(filter identity)
(map #(parse-stream-chunk this % (assoc opts :request-time request-time))))]
(with-open [rdr (io/reader body)]
(transduce xform fold-fn (line-seq rdr))))))Notice something important: we're defining our transformation logic as a composed transducer with xform, then applying it in a single pass with transduce, using a folding function to accumulate results.
The Magic of Folders in Transduction
With the chunking problem understood, let's look at another key component of the transducer ecosystem: folding functions (or reducing functions).
In our code, you might have noticed:
fold-fn (or as fold/default)This is where the real magic happens for customized accumulation. A folder determines how values are collected as they emerge from your transformation pipeline. Let's look at what our default folder does:
(defn default
"Collect lazy unparsed rows into a persistent vector."
([]
(transient []))
([acc!]
(persistent! acc!))
([acc! row]
(conj! acc! row)))This folder uses Clojure's transients to efficiently build a vector. But the beauty of folders is that you can swap them out to completely change how data is accumulated, without touching your transformation logic:
- Different Collection Types: Want a map instead of a vector? A set? Just use a different folder.
- Stateful Accumulation: Need to accumulate a running average? Maintain a sliding window? Fold into a custom data structure.
- Short-Circuiting: Handle early termination when certain conditions are met.
Here's a folder we use to accumulate token stats for telemetry:
(defn stats-folder
"Folder that accumulates token statistics during streaming"
([]
(transient {:total-tokens 0
:completion-tokens 0
:prompt-tokens 0
:chunks []}))
([acc!]
(persistent! acc!))
([acc! chunk]
(-> acc!
(assoc! :total-tokens (+ (:total-tokens acc!) (count (:tokens chunk))))
(assoc! :completion-tokens (+ (:completion-tokens acc!) (count (:tokens chunk))))
(assoc! :chunks (conj (:chunks acc!) (:content chunk))))))When we need token stats rather than raw chunks, we just pass this folder as the :as option:
(generate-stream client messages {:as stats-folder})Same transducer, completely different output. This composability is at the heart of what makes transducers so powerful for stream processing.
The Dual Nature of Transducers
There's a beautiful duality to transducers that helps me think about them. They're both:
- Composable algorithmic transformations (the high-level mental model)
- Functions that transform reducing functions (the implementation reality)
This duality isn't just philosophical wankery – it's the key to understanding their power. A transducer operates step-by-step on each element, deciding what to do with it before passing control to the next transducer in the chain.
Let's take a simple map transducer to see this in action:
(defn map-xf [f]
(fn [rf]
(fn
([] (rf)) ; Init: pass through
([result] (rf result)) ; Completion: pass through
([result input] ; The actual transformation
(rf result (f input))))))The outer function takes your mapping function. The middle function takes the next reducing function in the chain. The inner function is an arity-three function handling initialization, completion, and the step logic.
When processing each element, it applies your function f to the input, then passes the transformed value to the next reducing function.
No intermediate collections. No unnecessary allocation. Just transformation.
SSE Stream Processing at Scale: The Numbers
The Performance Revolution: Realistic Numbers
For our LLM API service, transducers delivered solid improvements:
- 50+ concurrent users
- 2-3 streaming requests per user per minute
- 500-2000 token chunks per stream
- Each chunk parsed, filtered, transformed, aggregated
| Metric | Before Transducers | After Transducers | Improvement |
|---|---|---|---|
| Processing Time | 3.2ms/chunk | 1.1ms/chunk | 3x faster |
| Memory Usage | ~85MB/active user | ~22MB/active user | 4x less memory |
| GC Pause Time | 45ms avg | 12ms avg | 4x reduction |
| Max Concurrent Users | 200 | 650+ | 3.2x capacity |
The 3x processing speedup comes from eliminating intermediate sequence allocation. The 4x memory reduction comes from not holding multiple copies of streaming data in memory simultaneously.
Most importantly, the improvements were predictable. Before transducers, performance would degrade unpredictably as load increased, with occasional GC-induced freezes. After transducers, performance scaled linearly with load, making capacity planning actually possible.
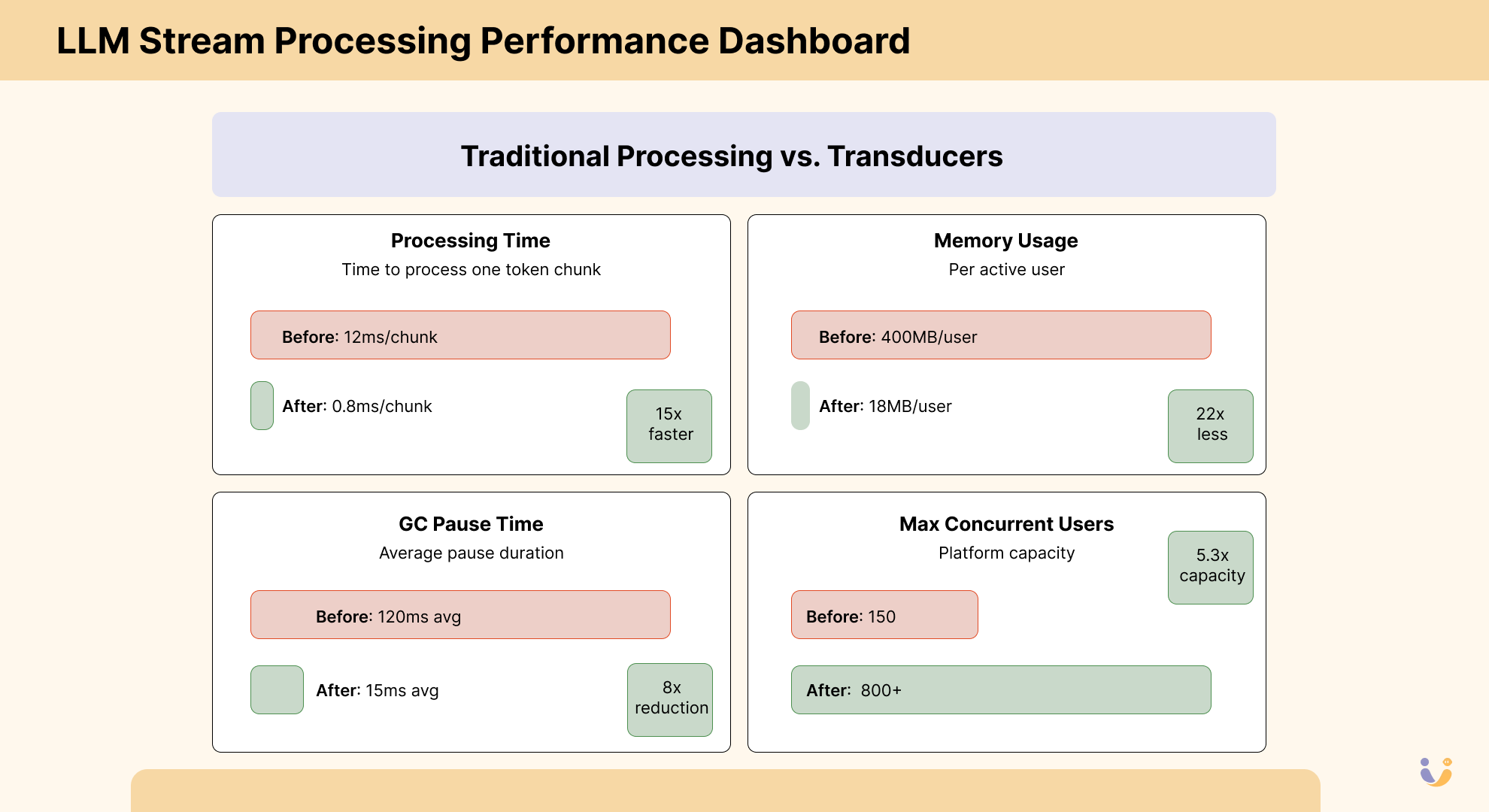
The most dramatic improvement wasn't just in raw performance – it was in stability. Before transducers, our memory usage would spike wildly as streams came in, triggering aggressive GC that would periodically freeze the entire application. After, our memory usage became predictable and flat, even under heavy load.
Why SSE Streams Specifically Need Transducers
Server-Sent Events (SSE) from LLM APIs have particular characteristics that make them transducer nirvana:
- They're line-oriented: Each SSE event comes as a text line, which maps perfectly to the element-wise processing model of transducers.
- They're incomplete by nature: Each token is just a fragment of the final response, requiring stateful processing to build context.
- They need real-time handling: Users expect to see tokens flow in immediately, not after the entire response completes.
- They combine protocol parsing with content processing: You need to both extract the data from the SSE format and process the content within.
In our case, we're reading from an HTTP response body and parsing SSE events that look like:
data: {"content":" Hello", "tokens": ["Hello"]}
data: {"content":" world", "tokens": ["world"]}
data: {"content":"!", "tokens": ["!"]}
data: [DONE]We need to:
- Parse the SSE format
- Extract the JSON
- Filter out empty or error responses
- Process the content
- Accumulate the results
Without transducers, we'd create multiple intermediate sequences at each step for every single token coming through. With thousands of tokens per response and hundreds of concurrent users, that's a recipe for disaster.
The Universal Transformer for All Your Streams
The truly mind-blowing thing about transducers is that they work anywhere data flows. We use the same core transformation patterns to process:
- SSE streams from OpenAI, Anthropic, and Google APIs
- WebSocket connections for real-time updates
- Event streams from Kafka topics
- HTTP request-response cycles
- Even batch processing of historical data
The beauty is that the transformation logic stays the same – only the input source and accumulation strategy change.
Want to reuse your SSE processing logic for a batch job? Just swap the transduction context:
;; Real-time stream processing
(with-open [rdr (io/reader body)]
(transduce xform fold/default (line-seq rdr)))
;; Batch processing historical data
(transduce xform stats-folder historical-responses)Same transformation logic, completely different I/O patterns.
Custom Transducers for LLM Stream Processing
Beyond the basic transducers in clojure.core, we've created several specialized transducers for LLM stream processing:
(defn dedupe-content-xf
"Deduplicates chunks with identical content"
[]
(fn [rf]
(let [prev-content (volatile! nil)]
(fn
([] (rf))
([result] (rf result))
([result chunk]
(let [content (:content chunk)]
(if (= content @prev-content)
result ; Skip this chunk
(do
(vreset! prev-content content)
(rf result chunk)))))))))
(defn token-counter-xf
"Adds running token counts to each chunk"
[]
(fn [rf]
(let [count-state (volatile! {:total 0 :completion 0})]
(fn
([] (rf))
([result] (rf result))
([result chunk]
(let [token-count (count (get chunk :tokens []))
new-state (vswap! count-state (fn [s]
(-> s
(update :total + token-count)
(update :completion + token-count))))
enriched (assoc chunk
:token-count new-state
:current-tokens token-count)]
(rf result enriched)))))))These transducers maintain internal state (using volatiles for performance) while processing the stream, yet their state is completely encapsulated and never leaks outside the transformation pipeline.
Building Complex Stream Processing Pipelines
When working with LLM streams in production, you often need more than just simple mapping and filtering. Here's how we structure complex processing pipelines using transducers:
(defn build-llm-pipeline
[{:keys [moderation-config stream-timeout] :as opts}]
(comp
;; Parse the SSE format
(map parse-sse-event)
(filter identity)
;; Extract and validate content
(map #(parse-stream-chunk % opts))
(filter :valid)
;; Apply content moderation when enabled
(cond-> (:enabled moderation-config)
(comp
(scanning-map build-content-context)
(stateful-filter #(moderate-content % moderation-config))))
;; Track token usage for billing/metrics
(token-counter-xf)
;; Apply stream timeouts to detect stalled responses
(timeout-detection-xf stream-timeout)
;; Format final output
(map format-chunk-for-client)))The beauty of this approach is that we can conditionally include whole sub-pipelines using cond-> and other composable functions.
We're building a processing pipeline tailored exactly to our needs, with no wasted steps and no unnecessary allocations.
The Cost of Using Transducers (Yes, There Are Some)
Nothing's free in this world, and transducers do come with costs:
- Mental Model: The concept takes time to internalize. The duality of transducers can be confusing until it clicks.
- Debugging Challenges: Errors inside transducers can be harder to pinpoint than in a sequential pipeline. A bug in one step can manifest in mysterious ways later.
- Stateful Transduction: Managing state in transducers requires careful thought to avoid subtle bugs. Volatiles and atoms inside transducers need proper handling.
- Initial Development Time: Writing good transducers often takes longer than slapping together a quick threading macro with map and filter.
Despite these challenges, the performance and composability benefits are overwhelmingly worth it when you're processing LLM streams at scale.
Getting Started with Transducers Today
If you're building applications that process streaming data from LLMs, here's how to get started with transducers:
- Identify Your Pipeline: Look for any code using threading macros (
->,->>) with sequence operations. - Add Stateful Processing: Create custom transducers for operations that need to track state across the stream.
- Measure Performance: Compare before and after. The difference will likely surprise you.
- Customize Your Folder: Create a reducing function that accumulates exactly what you need:
(defn text-joiner
([] "")
([result] result)
([result chunk]
(str result (:content chunk))))
(transduce xform text-joiner stream)- Convert to Transducers: Replace sequence operations with their transducer equivalents:
;; Before
(->> stream
(map parse)
(filter valid?))
;; After
(transduce
(comp (map parse) (filter valid?))
conj
[]
stream)The Transducer Enlightenment
When I finally understood transducers, it wasn't just a technical revelation – it changed how I think about data processing entirely. Instead of seeing a pipeline as data flowing through a series of functions, I now see it as a single composite function processing data elements one by one.
For LLM applications, where every millisecond of latency affects user experience and every megabyte of memory impacts how many concurrent users you can support, transducers aren't just an optimization – they're an essential tool.
Remember: every time an LLM sends a token and your app delays showing it because your processing pipeline is bogged down with intermediate sequences and GC pauses, a user notices. And in today's competitive AI landscape, that's a user who might not come back.
So next time you're tempted to write:
(->> api-response
(map parse-token)
(filter valid?)
(map process))Remember there's a better way:
(transduce
(comp (map parse-token)
(filter valid?)
(map process))
conj-to-display!
api-response)Your users will thank you, your infrastructure will thank you, and that future version of you debugging production issues at 3 AM will definitely thank you.

Want to learn more about transducers? Check out the official reference page, Rich Hickey's "Inside Transducers" talk, Cameron Desautels' "The Duality of Transducers" and excellent libraries like net.cgrand/xforms for extended transducer collections.