Database Deep Dive - The Beginning
Chasing the NoSQL hype nearly broke my startup—until I learned why relational databases, built on solid mathematics, power everything from MVPs to global apps. Explore the timeless lessons of data integrity, scalability, and the enduring genius of Ted Codd’s model.

When I started my professional journey almost a decade ago, I fell prey to the marketing gimmick of NoSQL databases. We were building a peer-to-peer marketplace, and MongoDB with Node.js was all the rage back then.
Everyone was talking about it—no schema migrations, no thinking about data modeling, just "build the model as we go." They promised horizontal scalability, and I was young and optimistic, convinced I could build anything.
So I convinced the founders and my engineering manager to use MongoDB as our primary database. This was back when MongoDB didn't even support transactions properly. In my youthful hubris, I thought we could build our own transaction layer on top of MongoDB. How hard could it be?
All of this worked fine... until we started seeing real users and business needs began changing rapidly.
What seemed like a brilliant architectural decision became a nightmare of data inconsistency, impossible queries, and sleepless nights trying to maintain referential integrity across a document store that was never designed for complex relationships.
The whole experience was great for learning about core database concepts the hard way—but it wasn't good for my mental health or the business.
This painful experience taught me why Ted Codd's relational model, conceived in 1969 and published in 1970, remains the gold standard for database design.
Let me take you on a journey through the elegant mathematics and practical wisdom that makes relational databases the backbone of nearly every serious application you've ever used.
The Problem That Started It All: When Databases Were Tightly Coupled Nightmares
To understand why the relational model was revolutionary, we need to step back to the 1960s. Picture yourself as a programmer working on an IBM mainframe, trying to build a database application.
You're not just writing application logic—you're intimately concerned with how data is physically stored on disk, how records are linked together with actual pointers, and exactly which data structures to traverse to answer a query.
Early database management systems like IDS (Integrated Data Store) and IMS (Information Management System) suffered from what we now call "tight coupling" between logical and physical layers. If you wanted to store customer records, you had to decide upfront: Should this be a hash table for fast lookups, or a B-tree for range scans? Make the wrong choice, and you'd have to rewrite not just the storage layer, but all the application code that navigated those data structures.
The CODASYL Wars: When Database Architects Fought Like Philosophers

The tension came to a head at a famous 1974 workshop in Michigan, where the database community split into two camps. On one side were the CODASYL (Conference on Data Systems Languages) advocates, who believed in explicit pointer-based navigation through hierarchical data structures. Think of it as forcing every query to traverse a linked list manually—fast if you know exactly where you're going, catastrophic if you need to search or change your access patterns.
On the other side stood Ted Codd and the relational camp, arguing for a mathematical foundation based on set theory and predicate logic. The CODASYL folks dismissed this as academic nonsense: "No mere mortal programmer will be able to understand your newfangled languages," they argued. "You won't be able to build an efficient implementation."
History, of course, proved them spectacularly wrong.
Enter Ted Codd: The Mathematician Who Solved Database Chaos

Edgar F. Codd wasn't originally a computer scientist—he was a mathematician who joined IBM Research and watched programmers repeatedly rewrite database applications every time the underlying storage changed. His breakthrough insight was profound in its simplicity:
What if we could separate what we want from how we get it?
In 1970, Codd published "A Relational Model of Data for Large Shared Data Banks" in Communications of the ACM. This paper didn't just propose a new database design—it introduced three revolutionary concepts that still govern database design today:
01: Structure: Relations as Mathematical Sets
Instead of forcing programmers to think about physical storage, Codd proposed storing data in relations—essentially tables where each row represents an entity and each column represents an attribute. But these aren't just tables; they're mathematically rigorous sets with specific properties:
- Unordered: Unlike arrays, relations have no inherent ordering, giving the database engine freedom to optimize storage and retrieval
- Unique identification: Every tuple (row) can be uniquely identified by a primary key
- Atomic values: Each cell contains a single, indivisible value (though modern SQL has relaxed this constraint)
-- This simple table represents a relation in Codd's model
CREATE TABLE Artist (
id INTEGER PRIMARY KEY,
name VARCHAR(255) NOT NULL,
year INTEGER CHECK (year > 1900),
country VARCHAR(100)
);02: Integrity: Constraints That Prevent Chaos
Codd understood that data without rules is just organized chaos. The relational model includes built-in mechanisms for maintaining data integrity:
- Entity integrity: Primary keys ensure every row is uniquely identifiable
- Referential integrity: Foreign keys ensure relationships between tables remain consistent
- Domain constraints: Data types and check constraints ensure values make sense
This is where my MongoDB nightmare began to make sense. Without these built-in integrity mechanisms, I was constantly writing application code to maintain consistency—code that was bug-prone, incomplete, and impossible to enforce across multiple applications accessing the same data.
03: Manipulation: The Power of Declarative Queries
Perhaps most importantly, Codd introduced the idea of data independence. Instead of writing procedural code that navigates data structures, developers could express what they wanted in a high-level, declarative language. The database engine would figure out the optimal way to retrieve that data.
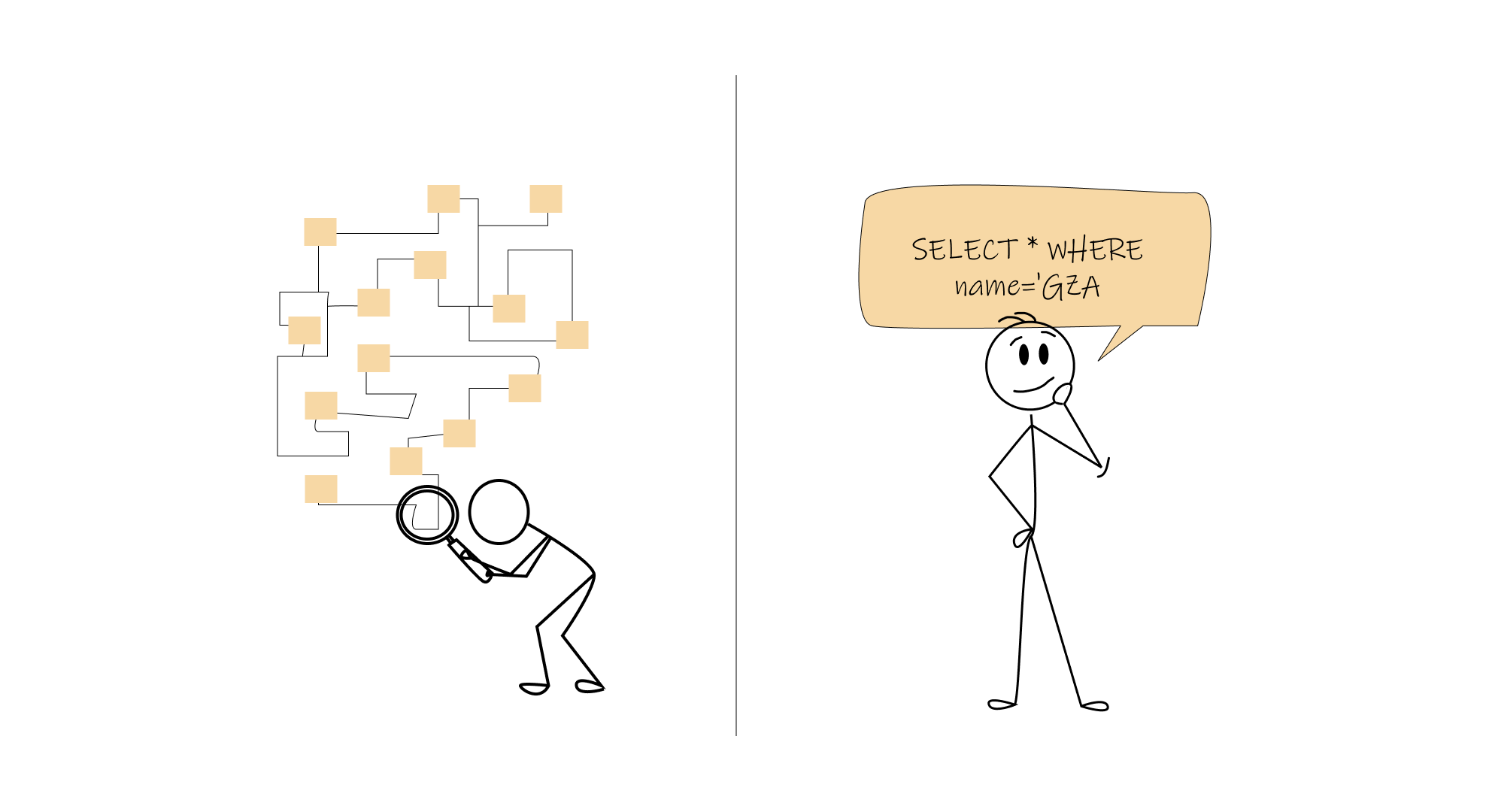
# The old way: Procedural navigation
for line in file.readlines():
record = parse(line)
if record[0] == "GZA":
print(int(record[1]))
sql-- The relational way: Declarative query
SELECT year FROM artists WHERE name = 'GZA';Relational Algebra: The Mathematical Foundation That Powers Every SQL Query
Underneath SQL's readable syntax lies relational algebra—a collection of mathematical operations that can express any possible query on relational data. Understanding these operations is crucial because modern query optimizers still think in terms of relational algebra when deciding how to execute your queries.
The Seven Fundamental Operations
Selection (σ): Filter rows based on conditions
σ(name='Wu-Tang Clan')(Artists)
-- SQL: SELECT * FROM Artists WHERE name = 'Wu-Tang Clan'Projection (π): Choose specific columns
π(name,year)(Artists)
-- SQL: SELECT name, year FROM ArtistsUnion (∪): Combine two compatible relations
R ∪ S
-- SQL: SELECT * FROM R UNION SELECT * FROM SIntersection (∩): Find common tuples
R ∩ S
-- SQL: SELECT * FROM R INTERSECT SELECT * FROM SDifference (−): Find tuples in first relation but not second
R − S
-- SQL: SELECT * FROM R EXCEPT SELECT * FROM SCartesian Product (×): All possible combinations
R × S
-- SQL: SELECT * FROM R CROSS JOIN SJoin (⋈): Combine related tuples
R ⋈ S
-- SQL: SELECT * FROM R JOIN S ON R.key = S.keyWhy This Mathematical Foundation Matters?
When you write an SQL query, the database engine converts it into relational algebra operations, then uses these mathematical properties to optimize execution.
For example:
-- Original query
SELECT a.name, b.title
FROM artists a
JOIN albums b ON a.id = b.artist_id
WHERE a.year > 1990;
-- The optimizer might rewrite this as:
π(name,title)(σ(year>1990)(Artists) ⋈ Albums)
-- Instead of: σ(year>1990)(π(name,title)(Artists ⋈ Albums))
This seemingly simple transformation can mean the difference between scanning millions of rows and examining just a few thousand.
The Power of Data Independence: Why Relational Databases Scale Through Decades
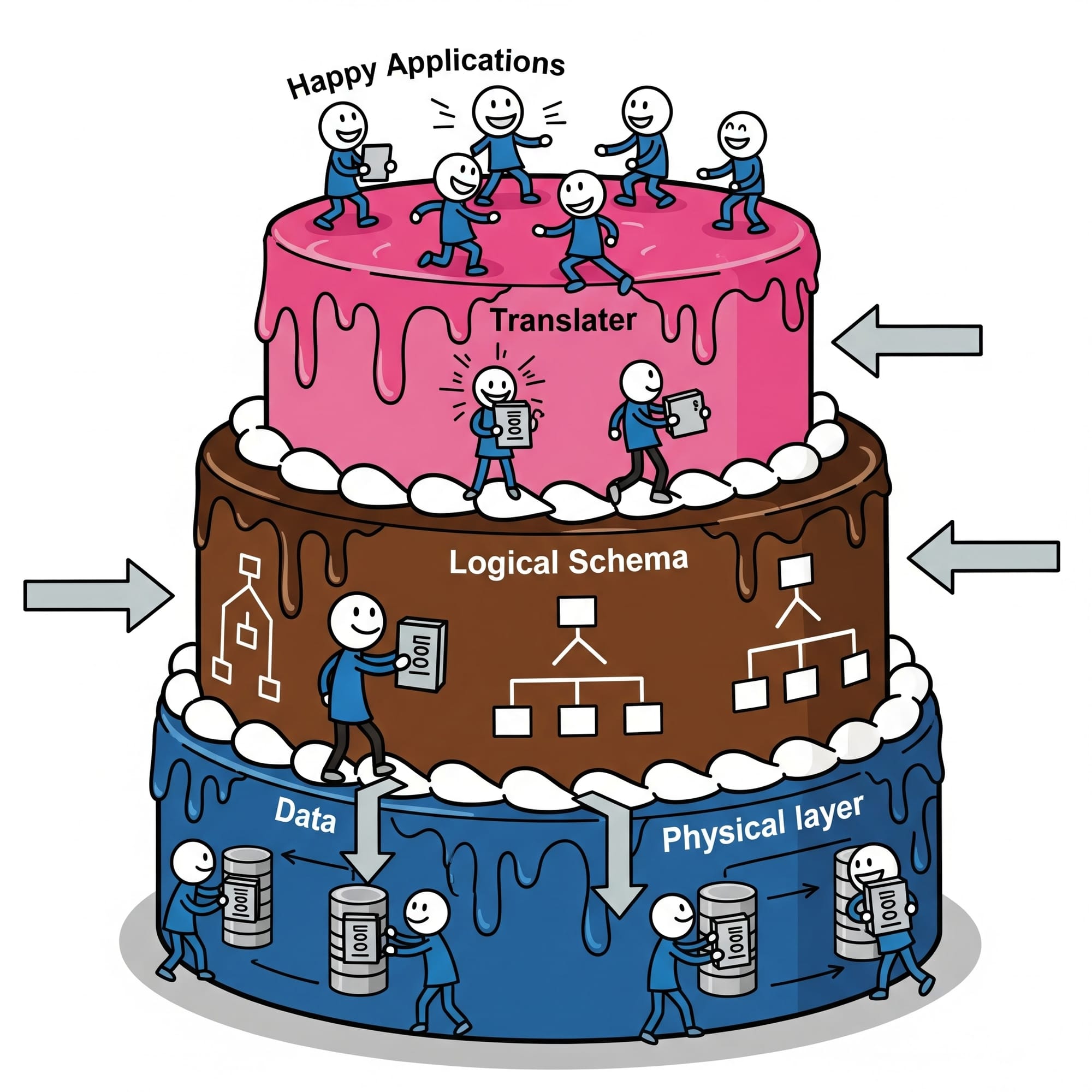
One of Codd's most prescient insights was data independence—the idea that applications should be insulated from changes in data storage and organization. The relational model achieves this through multiple layers of abstraction:
Physical Data Independence
Your application doesn't care whether data is stored on spinning disks, SSDs, or distributed across a cluster. The database engine handles all physical storage optimization:
- Storage formats: Row-based, column-based, or hybrid storage
- Indexing strategies: B-trees, hash indexes, bitmap indexes
- Compression: Dictionary encoding, run-length encoding, delta compression
- Partitioning: Horizontal, vertical, or functional partitioning
Logical Data Independence
Applications access data through views and logical schemas that can evolve independently of the underlying table structure:
-- Physical tables might be complex and normalized
CREATE TABLE artist_details (...);
CREATE TABLE artist_metadata (...);
CREATE TABLE artist_social_profiles (...);
-- But applications see a simple, logical view
CREATE VIEW artists AS
SELECT d.name, d.year, m.genre, s.twitter_handle
FROM artist_details d
JOIN artist_metadata m ON d.id = m.artist_id
LEFT JOIN artist_social_profiles s ON d.id = s.artist_id;This independence is why 50-year-old COBOL applications can still run against modern PostgreSQL databases, and why your Rails application doesn't break when your DBA adds an index or repartitions a table.
When NoSQL Makes Sense (And When It Doesn't)
My MongoDB disaster doesn't mean NoSQL databases are inherently evil. They solve real problems—just not the problems I thought I had. Here's when each approach shines:
Choose NoSQL When:
- Rapid prototyping: You genuinely don't know your data model yet
- Massive scale: You need to distribute across hundreds of nodes
- Specialized workloads: Document storage, graph traversal, time-series data
- Simple queries: You mostly read/write individual documents by key
Choose Relational When:
- Complex relationships: Your data has intricate connections
- ACID transactions: You need strong consistency guarantees
- Ad-hoc queries: Users need to slice and dice data in unpredictable ways
- Reporting and analytics: You need to join, aggregate, and analyze
- Multiple applications: Different systems need to access the same data
The Document Model Trap: Why "Schema-less" Often Means "Schema-on-Read"
The document model promises flexibility, but that flexibility comes with hidden costs:
// Looks flexible at first...
{
"artist": "GZA",
"albums": ["Liquid Swords", "Beneath the Surface"]
}
// But what happens when you need complex queries?
// Find all albums released in 1995 by artists from New York?
// Now you need to denormalize everything...
{
"artist": {
"name": "GZA",
"city": "New York",
"albums": [
{
"title": "Liquid Swords",
"year": 1995,
"collaborations": [
{"artist": "Method Man", "city": "Staten Island"},
{"artist": "Inspectah Deck", "city": "Staten Island"}
]
}
]
}
}What started as "schema-less" quickly becomes a rigid, denormalized mess where every query requires careful navigation of nested structures. You've traded schema evolution problems for query complexity problems—and query complexity is far harder to solve.
Vector Databases: The New Kid That's Actually an Old Friend
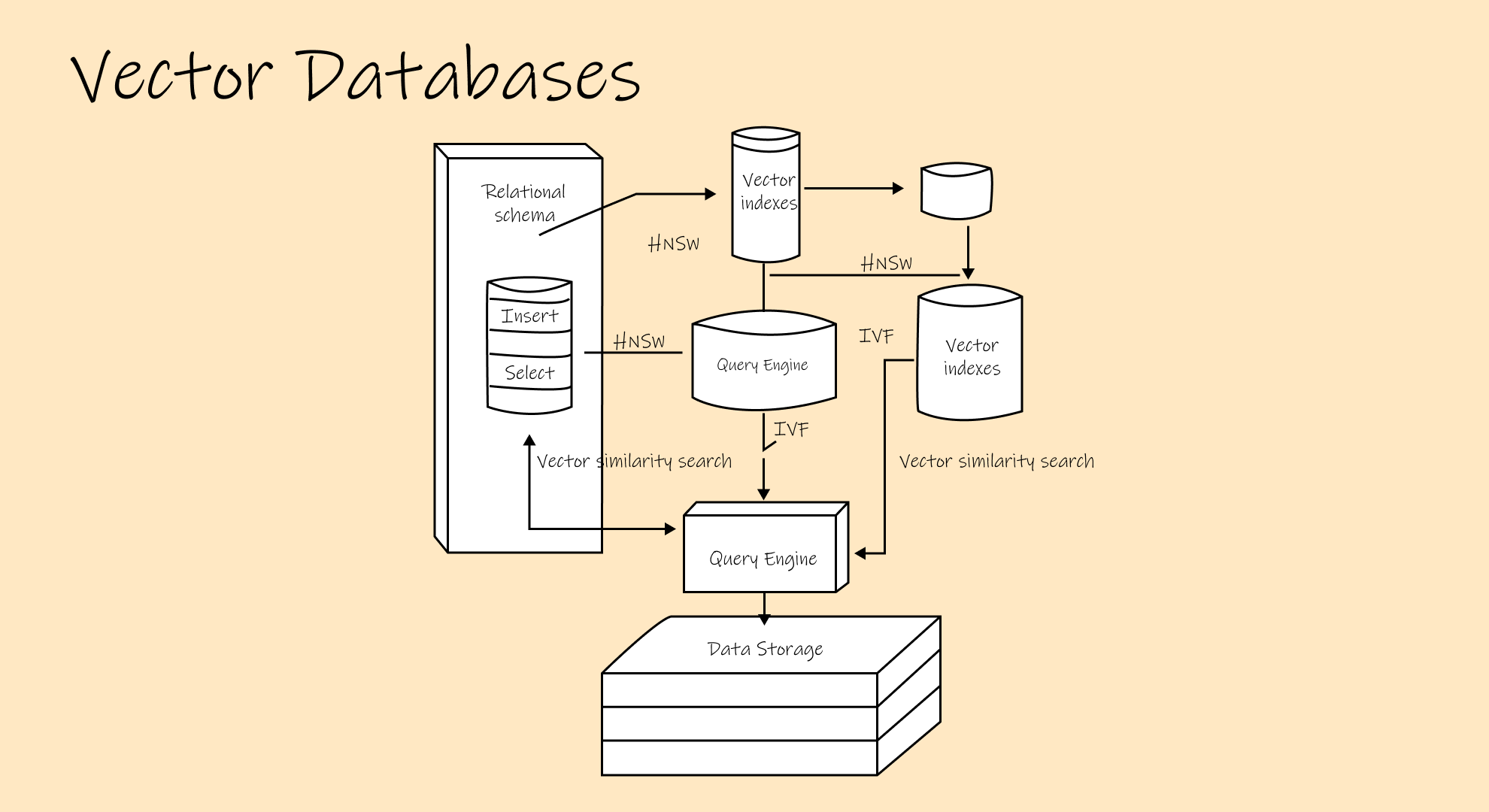
The latest "revolution" in database technology is vector databases for AI and machine learning workloads. But here's the thing: most "vector databases" are actually relational databases with specialized indexing for high-dimensional arrays.
-- PostgreSQL with pgvector extension
CREATE TABLE albums (
id SERIAL PRIMARY KEY,
name TEXT,
embedding VECTOR(768) -- High-dimensional representation
);
-- Semantic search using vector similarity
SELECT name, embedding <-> query_vector AS similarity
FROM albums
ORDER BY embedding <-> query_vector
LIMIT 10;The relational model's flexibility shines here: it can accommodate specialized data types (vectors) and operations (nearest neighbor search) without abandoning the mathematical foundation that makes complex queries possible.
Modern SQL: The Relational Model Evolved
Today's SQL isn't your grandfather's database language. Modern relational databases have embraced the best ideas from NoSQL while maintaining ACID guarantees and relational integrity:
-- JSON support for semi-structured data
SELECT name, metadata->>'genre' as genre
FROM artists
WHERE metadata @> '{"active": true}';
-- Window functions for analytics
SELECT name, year,
LAG(year) OVER (ORDER BY year) as prev_year,
year - LAG(year) OVER (ORDER BY year) as gap
FROM artists;
-- Common Table Expressions for complex queries
WITH RECURSIVE artist_hierarchy AS (
SELECT id, name, mentor_id, 1 as level
FROM artists WHERE mentor_id IS NULL
UNION ALL
SELECT a.id, a.name, a.mentor_id, ah.level + 1
FROM artists a
JOIN artist_hierarchy ah ON a.mentor_id = ah.id
)
SELECT * FROM artist_hierarchy;Practical Wisdom: Choosing PostgreSQL in 2025

When in doubt, choose PostgreSQL. Here's why:
- Feature complete: ACID transactions, complex queries, JSON support, full-text search
- Extensible: Add vector search, geospatial data, time-series optimizations as needed
- Mature: Decades of production hardening and optimization
- Standard compliant: Your SQL knowledge transfers everywhere
- Community: Massive ecosystem of tools, extensions, and expertise
PostgreSQL embodies Codd's vision while embracing modern requirements. It's simultaneously a traditional relational database and a modern multi-model system that can handle documents, graphs, vectors, and time-series data.
The Enduring Lesson: Mathematical Foundations Matter
My MongoDB nightmare taught me something profound: mathematical foundations matter. Codd's relational model isn't just some academic exercise—it's a proven framework for organizing and querying data that scales from startup MVPs to systems managing petabytes.
The seven operations of relational algebra, the guarantees of ACID transactions, and the elegance of declarative queries aren't constraints—they're leverage. They let you build complex applications on a foundation that's been tested by millions of developers over five decades.
Every time someone promises to "disrupt" databases with a new paradigm, they eventually end up reinventing aspects of the relational model. MongoDB added transactions. Cassandra added secondary indexes. NewSQL systems added distributed ACID guarantees. They all converge back to Codd's insights because the mathematical foundation is sound.
Your Next Database Decision
The next time you're choosing a database technology, ask yourself:
- Do I need complex relationships between entities? → Relational
- Do I need ACID transactions across multiple operations? → Relational
- Will multiple applications access this data? → Relational
- Do I need ad-hoc queries and reporting? → Relational
- Am I building for the long term? → Relational
Choose something else only when you have specific, well-understood requirements that relational databases can't meet. And even then, consider whether extending PostgreSQL might be simpler than adopting an entirely different data model.
Ted Codd's 1970 vision of data independence, mathematical rigor, and declarative queries isn't just database history—it's still the best foundation for building systems that need to evolve, scale, and last.
Don't repeat my MongoDB mistake. Build on the solid mathematical foundation that has powered everything from airline reservations to social networks for over half a century.
The relational model isn't just another approach to data storage. It's the approach that works. Every database eventually becomes relational or dies trying. The only question is whether you want to learn this lesson through painful experience or by studying the mathematical principles that make databases work.
The next time someone tells you that relational databases are "legacy technology," remind them that mathematics is also legacy technology—and it's not going anywhere.
References
- Codd, E.F. (1970). "A Relational Model of Data for Large Shared Data Banks." Communications of the ACM, 13(6), 377-387.
- Pavlo, A. (2024). "Lecture #01: Relational Model & Algebra." 15-445/645 Database Systems, Carnegie Mellon University. Course Materials
- Date, C.J. (2003). An Introduction to Database Systems (8th ed.). Addison-Wesley.
- Stonebraker, M. & Hellerstein, J.M. (1998). Readings in Database Systems (3rd ed.). Morgan Kaufmann.
- Gray, J. & Reuter, A. (1993). Transaction Processing: Concepts and Techniques. Morgan Kaufmann.
- PostgreSQL Global Development Group. (2024). "PostgreSQL Documentation." Retrieved from https://postgresql.org/docs/