Database Deep Dive: Storage
My database imploded and 50,000 records vanished. That panic-fueled night turned me from a clueless coder into someone who finally understood where data truly lives.

The Great Page Corruption Incident of 2019
It was 3 AM on a Tuesday when my phone exploded with alerts. Our main production database was hemorrhaging data faster than a leaky ship. Transactions were failing, users were locked out, and I was staring at PostgreSQL logs that made absolutely no sense. The error messages pointed to something called "page corruption" – a term that would haunt my dreams for weeks to come.
What I didn't realize at the time was that this disaster would teach me more about database storage internals than years of theory ever could. When you're debugging why 50,000 customer records seem to have vanished into thin air, you quickly develop a visceral understanding of how databases actually store data on disk.

That night, as I dove into the PostgreSQL documentation and started examining our actual data files on disk, I discovered something fascinating: databases aren't just magical black boxes that store your data somewhere in the cloud. They're intricate systems built on surprisingly simple concepts that, when you understand them, make the difference between panic and confidence when things go wrong.
The Foundation: Why Storage Matters More Than You Think
Most developers treat database storage like they treat their car engine – they know it's important, but they'd rather not look under the hood. This mindset works fine until the engine starts making weird noises, or in our case, until your database starts corrupting pages.
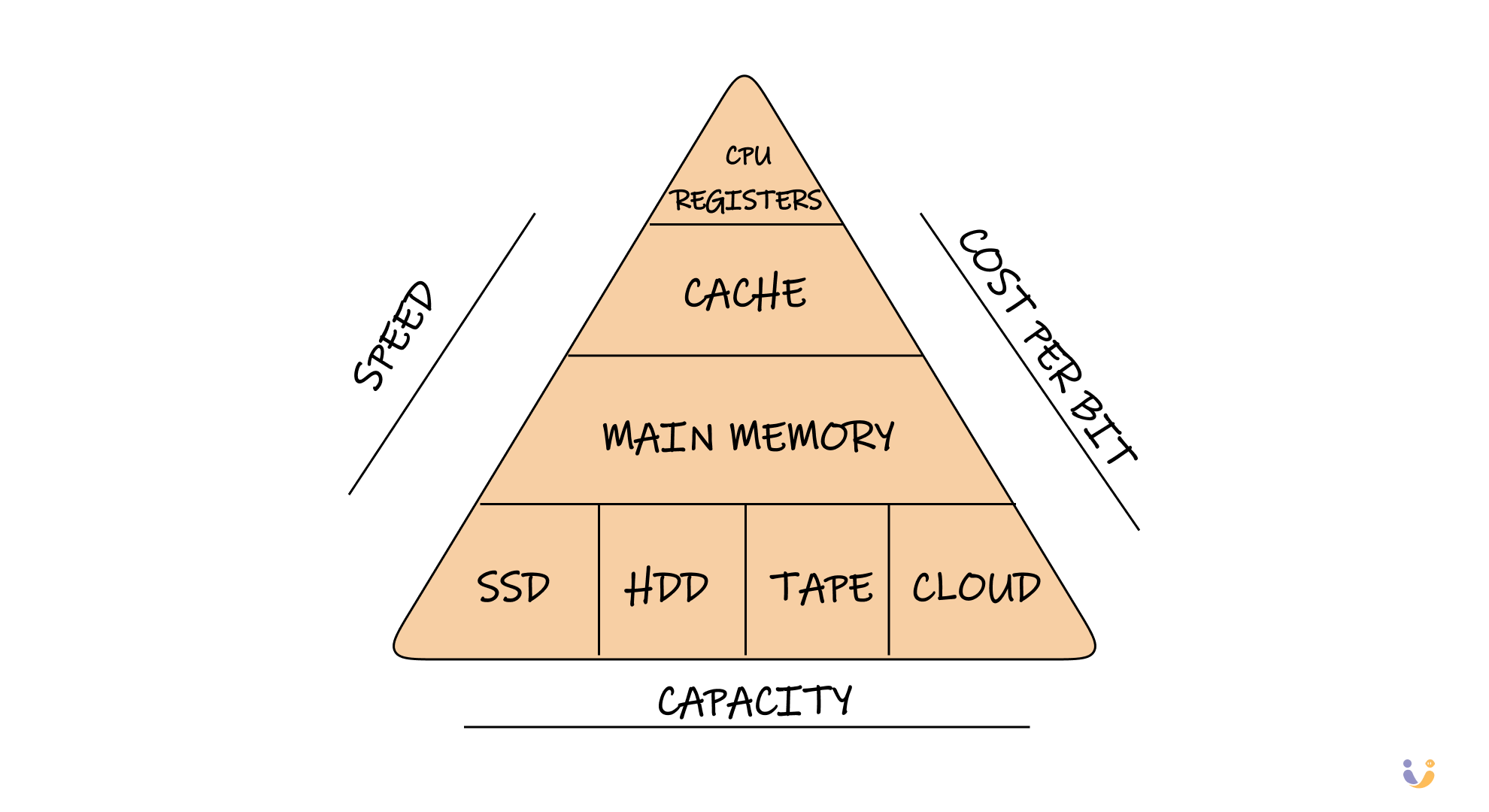
Database storage is fundamentally about one thing: orchestrating the eternal dance between memory and disk. Your CPU can only work with data that's in memory, but memory is volatile – pull the plug and everything disappears. Disk storage is permanent but painfully slow. The entire storage subsystem exists to make this relationship work smoothly.
Think about it this way: if reading from L1 cache takes 1 second, reading from DRAM takes about 4 seconds, reading from an SSD takes 4.4 hours, and reading from a traditional hard drive takes 3.3 weeks. These aren't just numbers – they represent fundamental constraints that shape every decision in database design.
The Anatomy of a Database File
During that fateful debugging session, I learned that PostgreSQL stores our precious customer data in files that live right there on the filesystem. Nothing magical about it – just regular files that you can see with ls. What makes them special is their internal structure.
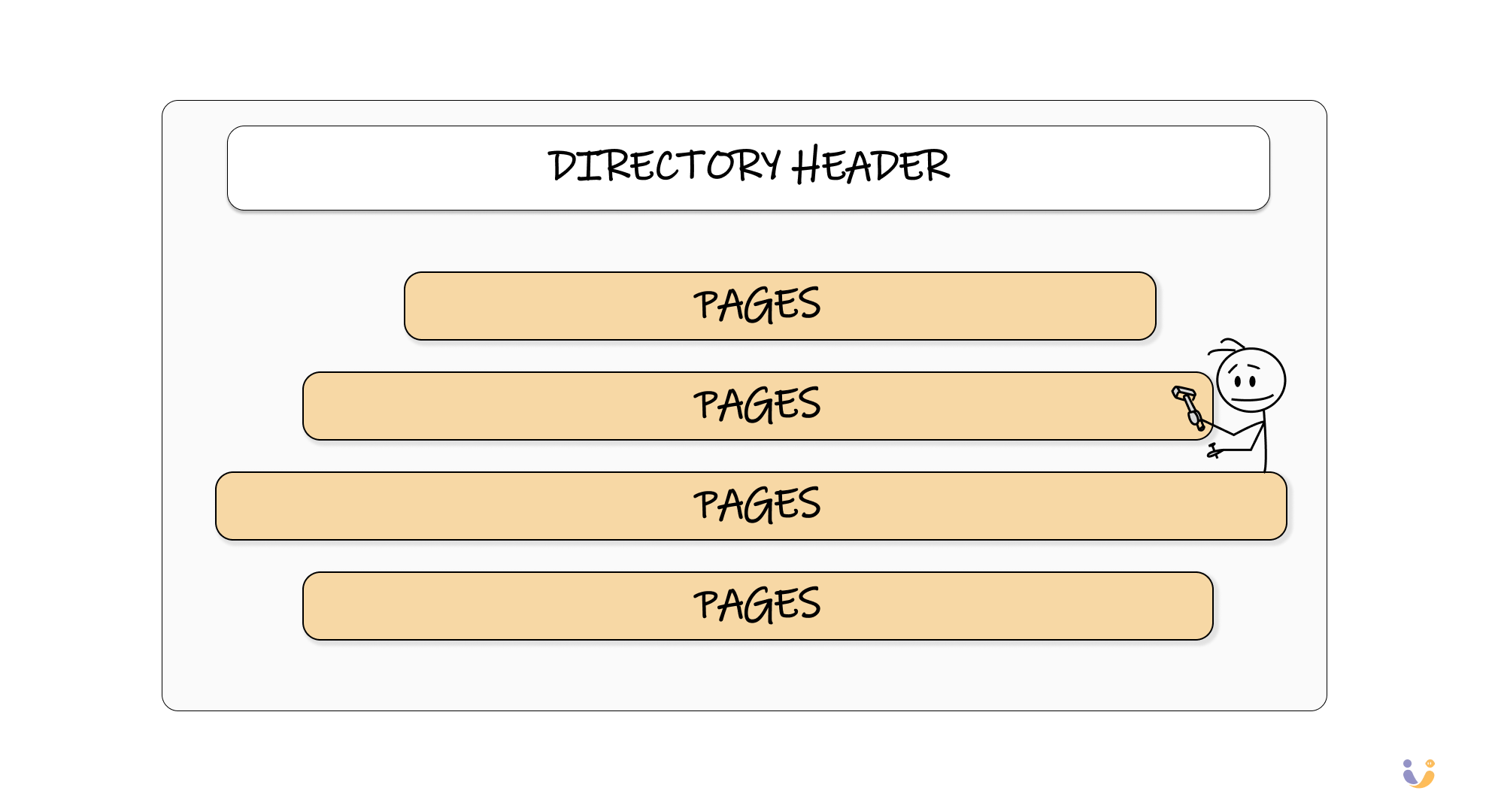
Every database file starts with a directory that acts like a table of contents. This directory tells the database where to find specific pieces of data, much like how a book's index helps you find specific topics. Below that directory, the file is divided into fixed-size chunks called pages.
These pages are typically 4KB, 8KB, or 16KB depending on your database system. PostgreSQL uses 8KB pages by default, which seemed arbitrary until I understood the reasoning. Page size is a fundamental tradeoff: larger pages mean fewer disk operations for sequential reads but more waste when you only need small amounts of data.
The Page: Where Data Actually Lives
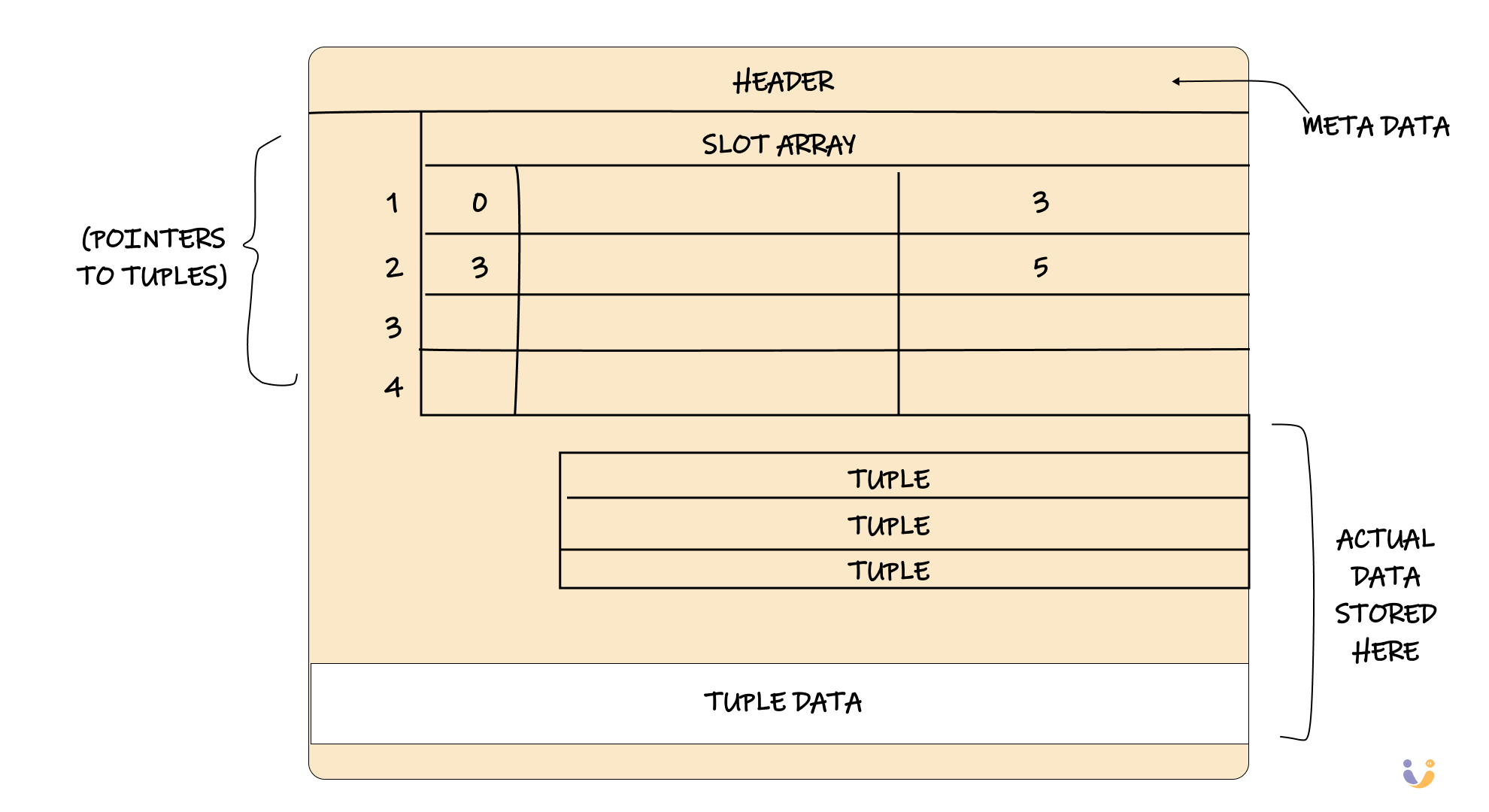
Here's where things get interesting. Each page has its own header containing metadata about what's inside. Think of it like a label on a filing folder that tells you what documents are stored inside without having to open it.
But the clever part is how data is organized within each page. Most databases use something called "slotted pages." Instead of just cramming data in sequentially (which would be a disaster when you delete something), they use an indirection layer.
The slot array maps logical positions to physical locations within the page. When you delete a tuple, you just mark its slot as empty without moving any other data around. When you insert new data, the database can reuse those empty slots. It's like having a smart filing system that automatically finds empty spots when you need to file new documents.
The Tuple: Your Data's Final Form
At the lowest level, your carefully crafted SQL records become sequences of bytes called tuples. Each tuple has its own header containing concurrency control information and a bitmap indicating which fields are NULL.
The attribute data follows in the order you specified when creating the table. This seems obvious, but it's actually a deliberate design choice. Some databases reorder attributes for better memory alignment or compression, but most stick with your original order for simplicity.
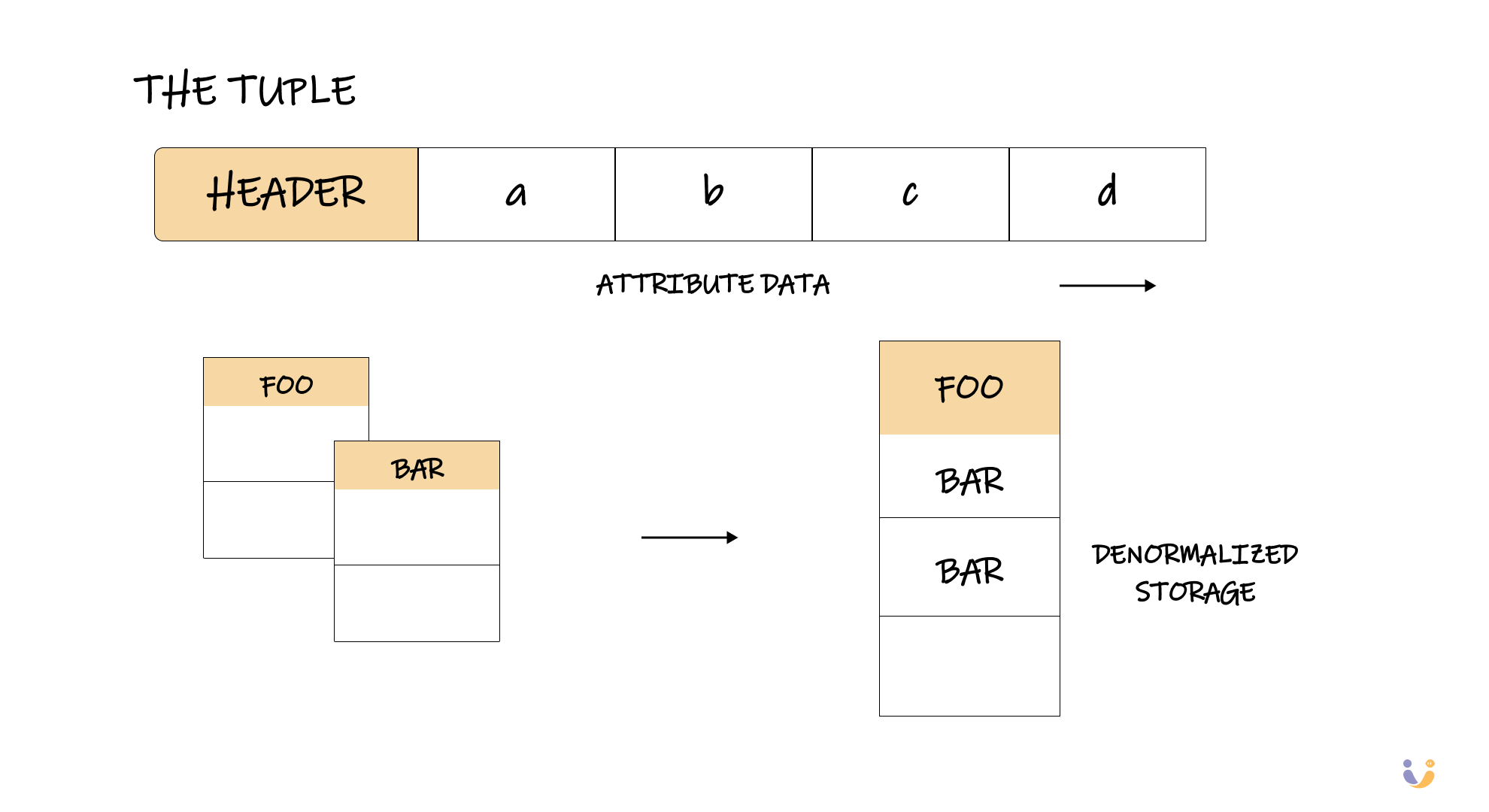
Here's something that blew my mind during the debugging session: databases can actually store related data together on the same page through a technique called denormalization. Instead of storing your users table and orders table separately, forcing expensive joins, a database could store each user's data alongside their recent orders on the same page.
[Visual: Before/after comparison showing separate foo and bar tables vs denormalized storage with foo data followed by related bar data]
This isn't just theoretical – IBM's System R did this in the 1970s, and modern NoSQL databases do it extensively without calling it "denormalization."
Record IDs: The GPS Coordinates of Your Data
Every piece of data needs an address, and in databases, that address is called a Record ID or Row ID. It's typically composed of a file ID, page ID, and slot number – essentially GPS coordinates for your data.
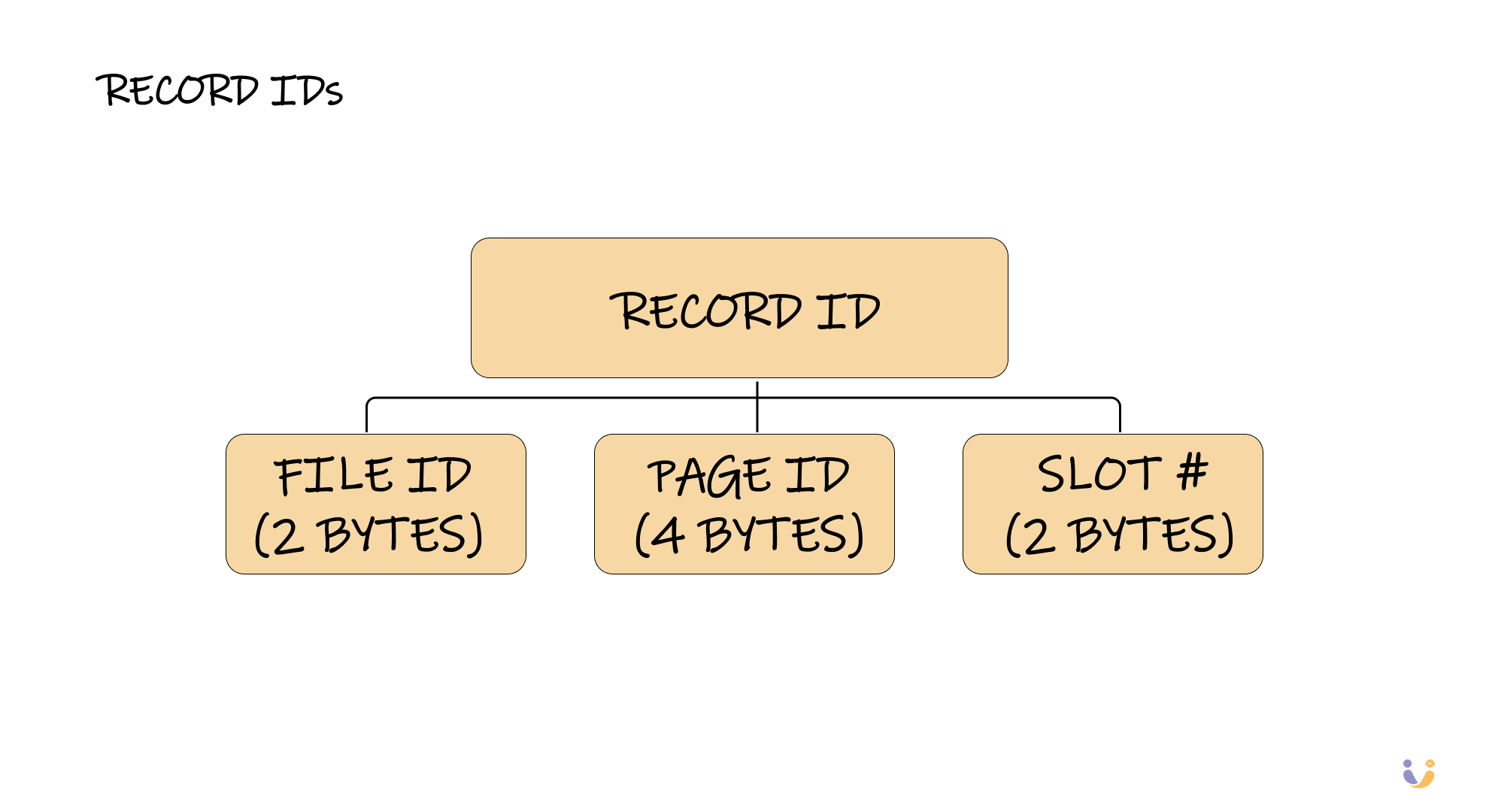
PostgreSQL calls these CTIDs, SQLite calls them ROWIDs, and SQL Server has something called %%physloc%%. The name doesn't matter – what matters is that these IDs provide a direct path to your data without expensive index lookups.
The Buffer Pool: Your Database's Memory Manager
Remember our memory vs disk problem? The buffer pool is how databases solve it. Think of it as a smart cache that keeps frequently accessed pages in memory while seamlessly fetching new pages from disk when needed.
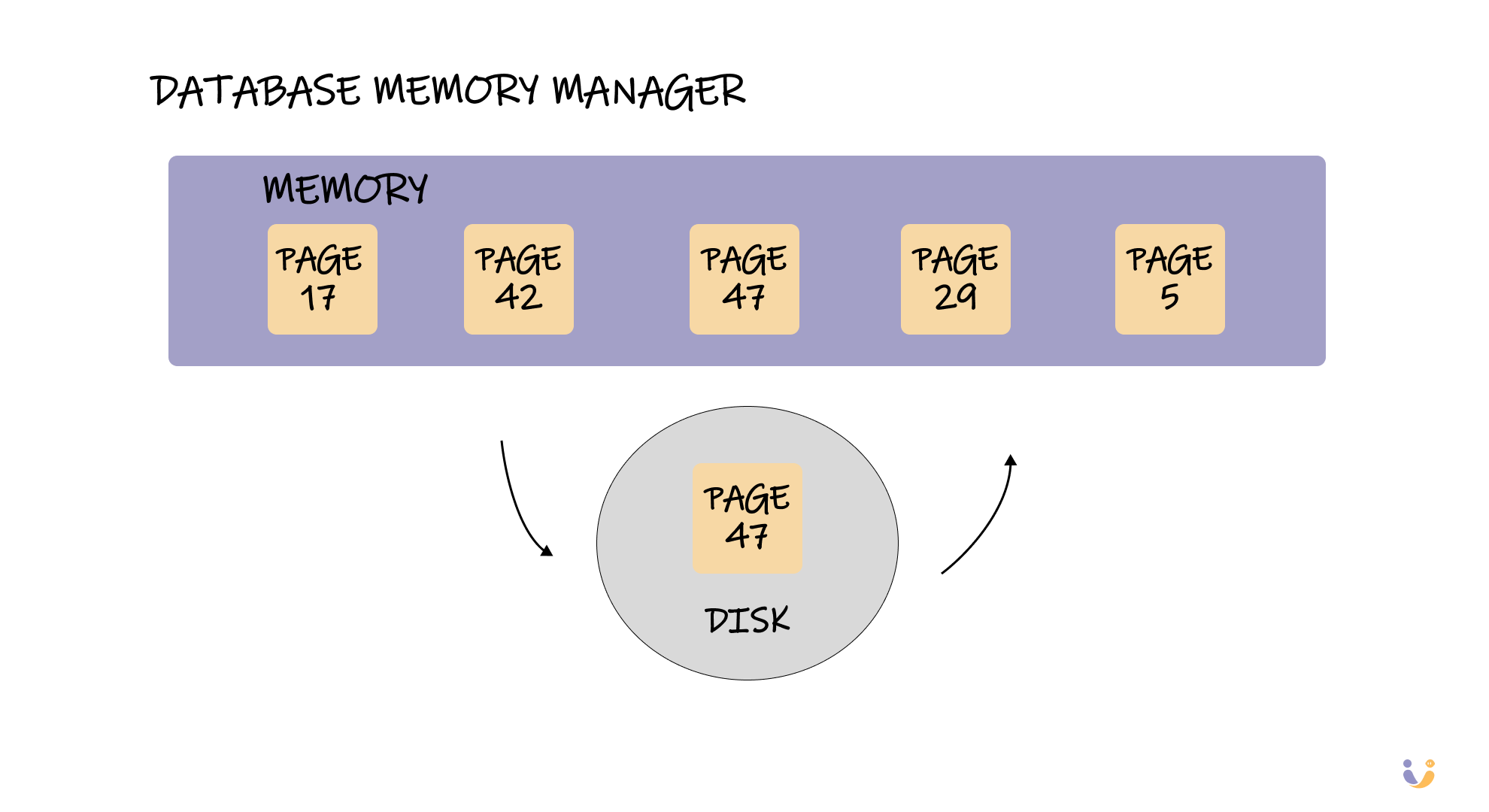
When your query asks for page #47, the execution engine first checks if it's already in the buffer pool. If not, it kicks off a disk read, updates the buffer pool, and returns a pointer to the data in memory. All of this happens transparently – your SQL doesn't need to know whether data is coming from memory or disk.
Sequential vs Random Access: The Performance Cliff
During that debugging night, I discovered something that seems counterintuitive: where your data is physically located on disk matters enormously. Reading data sequentially can be orders of magnitude faster than random access.
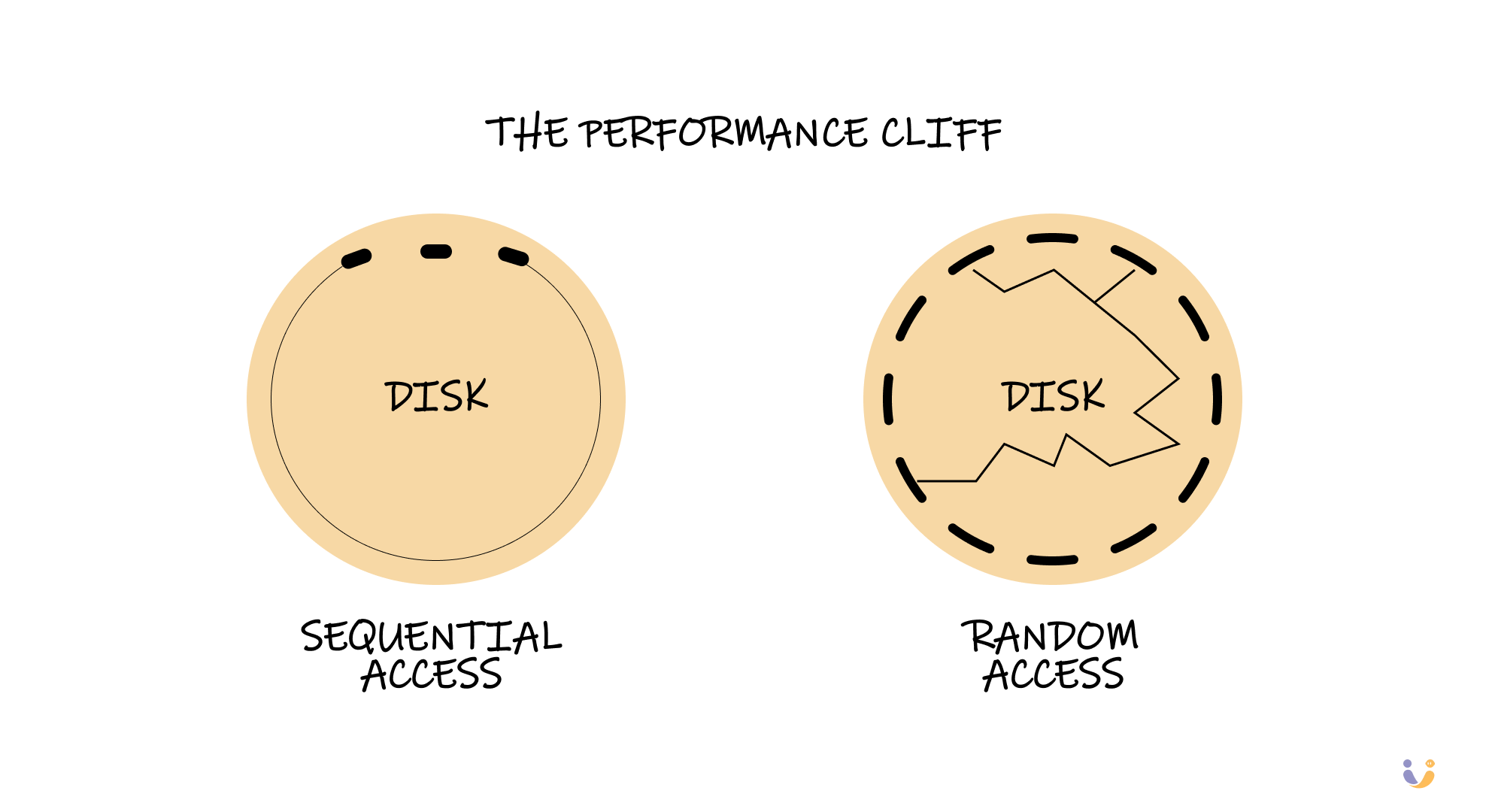
This is why database algorithms go to extraordinary lengths to minimize random disk access. They'll allocate large chunks of pages at once (called extents), write data sequentially even if it means writing it twice, and carefully organize data to maximize the chances that related information lives near each other on disk.
Solid-state drives have reduced this gap, but haven't eliminated it. Even on modern NVMe SSDs, sequential access is significantly faster than random access.
Hardware Pages vs Database Pages: The Hidden Complexity
Here's something that caught me off guard: there are actually three different concepts of "pages" in any database system. Hardware pages (usually 4KB), OS pages (also usually 4KB), and database pages (which can be larger).
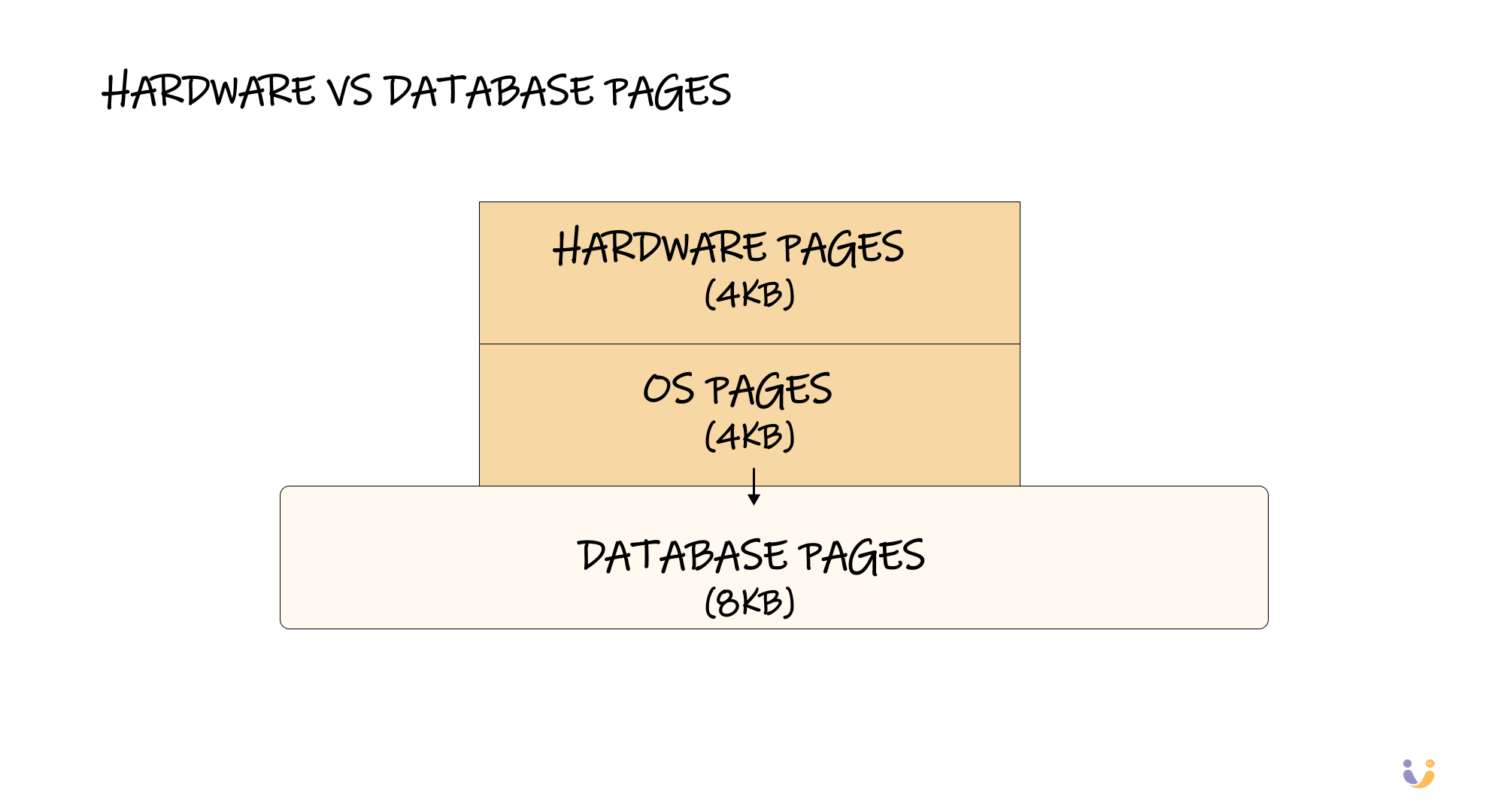
This creates an interesting problem: if your database page is 8KB but your hardware can only guarantee atomic writes of 4KB, what happens if your system crashes while writing a database page? You might get a "torn page" where only half the data makes it to disk.
Databases solve this through various techniques like write-ahead logging and checksums, but it illustrates how seemingly simple operations become complex when you consider the entire stack.
The Great Compaction Dilemma
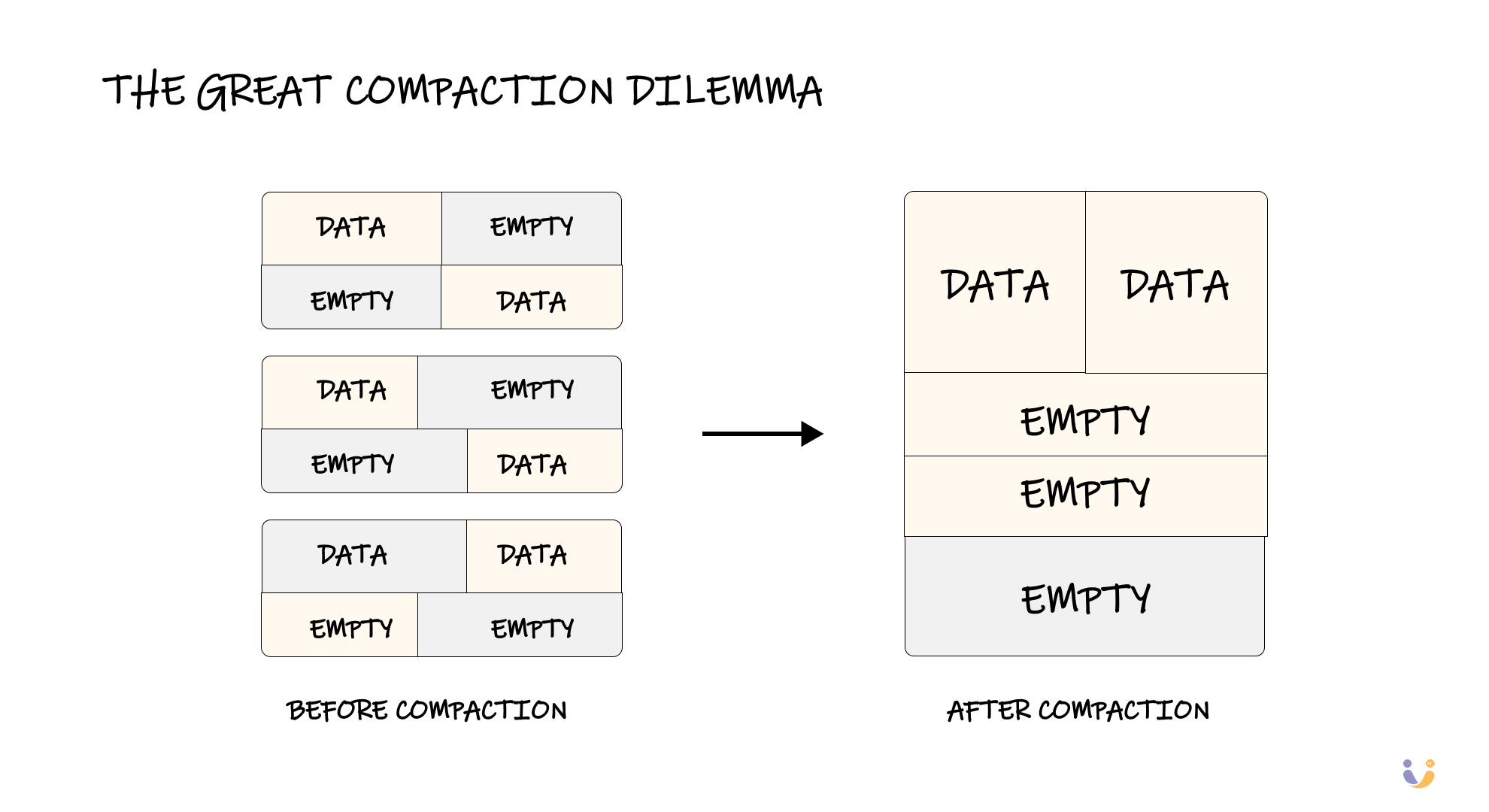
As data gets inserted, updated, and deleted, pages develop fragmentation. You end up with partially filled pages scattered throughout your database files. Some databases automatically compact this fragmentation, moving data around to fill empty spaces. Others leave it alone to avoid the performance cost of constantly moving data.
There's no right answer here – it's another fundamental tradeoff. Compaction reduces storage waste and can improve scan performance, but it requires holding locks and doing extra work that slows down your application.
Why This All Matters: Lessons from the Trenches
That page corruption incident I mentioned? It turned out to be caused by a failing disk controller that was silently corrupting random writes. Without understanding how PostgreSQL stored data on disk, I would have been completely lost. But because I understood pages, slots, and record IDs, I could:
- Identify exactly which pages were corrupted
- Understand why some data was recoverable and other data wasn't
- Write scripts to extract undamaged data from partially corrupted pages
- Implement monitoring to catch similar issues before they became disasters
More importantly, understanding storage internals changes how you think about performance. When you know that updating a single column might require rewriting an entire 8KB page, you start thinking differently about schema design. When you understand that related data stored on the same page can be accessed with a single disk read, you start seeing opportunities for denormalization.
Modern Innovations and Future Directions
Database storage isn't a solved problem. Intel's Optane persistent memory promised to blur the line between memory and storage before being discontinued in 2022. New technologies like CXL Type 3 offer byte-addressable memory that might not even be on your local machine.
These technologies could fundamentally change how we think about database storage. When the distinction between memory and disk disappears, many of the concepts we've discussed become obsolete. Buffer pools, page management, and even the concept of bringing data into memory might become historical artifacts.
The Bottom Line
Database storage might seem like an implementation detail, but it's the foundation everything else builds on. Understanding how your database physically stores and retrieves data transforms you from someone who writes SQL and hopes for the best into someone who can reason about performance, debug mysterious issues, and make informed architectural decisions.
That 3 AM debugging session was painful, but it taught me something invaluable: databases aren't magic. They're elegant solutions to fundamental computer science problems, built from understandable components that follow logical principles. Once you understand those principles, databases stop being black boxes and start being tools you can truly master.
The next time your database starts acting weird, don't just restart it and hope for the best. Dive into the storage layer. Look at the actual files on disk. Understand how your data is physically organized. You might just discover, like I did, that the path to database mastery runs straight through the storage engine.
References
- PostgreSQL Documentation - Database Physical Storage: https://www.postgresql.org/docs/current/storage.html
- CMU 15-445 Database Systems Course: https://15445.courses.cs.cmu.edu/
- Latency Numbers Every Programmer Should Know: https://gist.github.com/jboner/2841832
- Intel Optane Technology Overview: https://www.intel.com/content/www/us/en/architecture-and-technology/optane-memory.html
- System R: Relational Approach to Database Management: IBM Research Paper