Polylith Is the AI Architecture
Microservices hide context from AI assistants. Monoliths lack enforced boundaries. Polylith gives both at once — and hands you a machine-readable structural index no other architecture provides.
The first time Claude Code wired our auth interface into three components it had never seen before, I didn't touch a thing. It found the right namespace, followed the right conventions, used the right patterns — because it had read how the system was organised. Not because it was clever. Because the architecture was legible.
That moment made me think differently about what AI tooling actually needs from a codebase.
The microservices problem
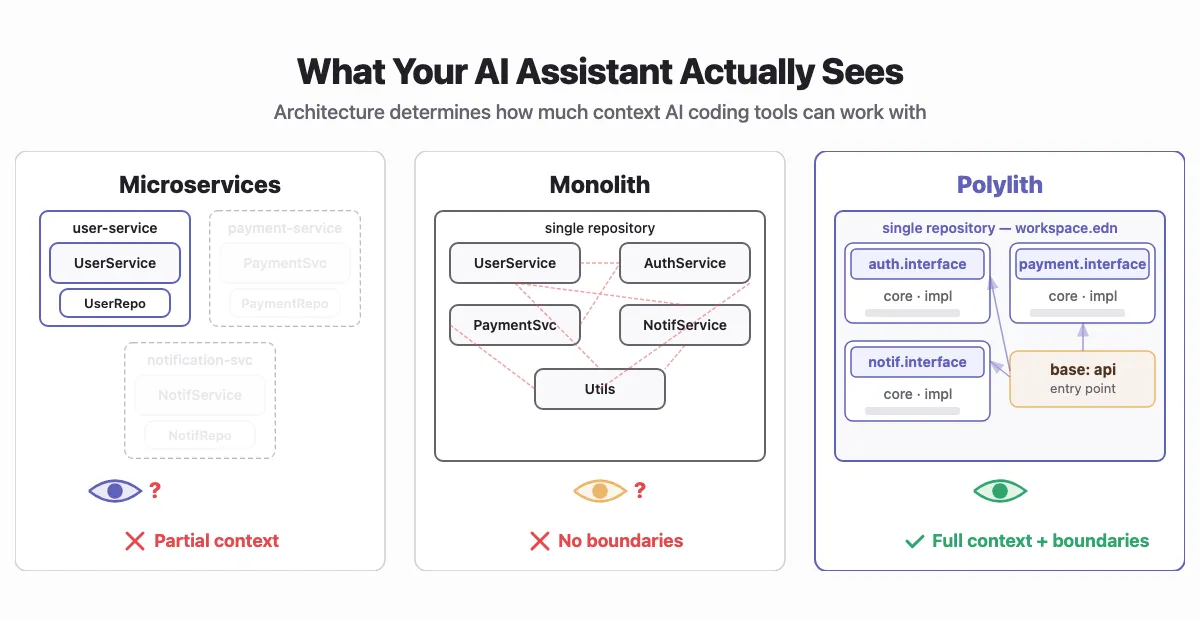
In a microservices setup, each service lives in its own repository. Clean separation. Independent deployments. The standard argument.
But when you open Claude Code on user-service, it can't see payment-service. It can't see notification-service. It knows the service in front of it and nothing else.
So it guesses. It invents conventions. It creates function signatures that don't match how the rest of your system works. It's not wrong. It's just working with incomplete information.
You spend time correcting those guesses. Not because the AI is bad. Because the architecture hid the context.
The research has started to quantify this. A 2023 Microsoft Research paper showed that drawing context from across a whole repository improves code completion by more than 10% compared to single-file approaches, in every setting tested. SWE-bench, the benchmark researchers use to evaluate AI agents on real GitHub issues, confirms the pattern: solving real problems requires navigating code spread across many files. The effective unit of AI reasoning for code is the repository, not the file.
Why do microservices limit AI coding assistant quality?
Each service lives in its own repository. The AI can only see the service in front of it — it guesses at conventions and patterns in the rest of the system.
Click to reveal answer
The monolith problem
Put everything in one repository and the AI can see everything. No more guessing about what lives in other services.
But traditional monoliths have a different problem: no enforced boundaries. Nothing stops code from calling anything else. The AI can see that UserRepository is used in 47 different places, and that AuthService has a private method some other class happens to reach into directly.
So it does what any reader of tangled code does: it looks at what's done and does more of the same. Messy architecture produces messy suggestions.
Stanford's "Lost in the Middle" study measured something related: language models degrade when relevant information is buried deep in a long context — performance forms a U-shape, strongest at the edges. An unstructured monolith creates exactly this condition. The information exists. The model can't reliably find it.
What Polylith is
Polylith is a component-based architecture that lives in a single repository. It originated in the Clojure ecosystem but the pattern isn't language-specific — Python Polylith brings the same architecture and tooling to Python, with support for Poetry, uv, Hatch, and other package managers. Each unit of logic is a component: isolated, with a single responsibility. The only thing another component can touch is the interface, a single namespace with exactly the functions you decided to make public. Bases are thin entry points that wire components into something deployable.
What is the Polylith architecture made of?
Three things: components (isolated units of business logic with a single interface namespace), interfaces (the public surface of each component), and bases (thin entry points that wire components into deployable applications).
Click to reveal answer
Every component exposes exactly what it wants through a single interface namespace. In Clojure, that namespace follows a predictable path: <top-namespace>.<component>.interface.
;; components/auth/src/com/acme/auth/interface.cljc
(ns com.acme.auth.interface
(:require [com.acme.auth.core :as core]))
(defn token [credentials]
(core/issue-token credentials))
(defn valid? [token]
(core/validate-token token))
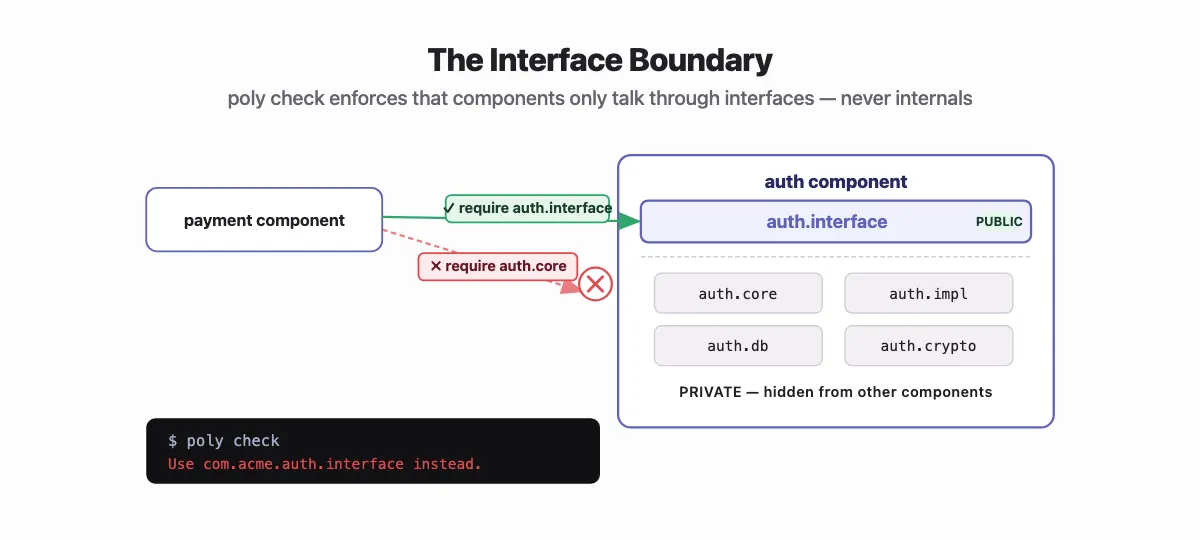
Two functions. That's the public surface of the entire auth component. Everything in core, impl, db is invisible. Consumers import com.acme.auth.interface. Nothing else.
Polylith enforces this. Try importing com.acme.auth.core directly from another component and poly check will tell you:
$ poly check
Error 101: Illegal dependency on namespace com.acme.auth.core in payment.
Not a convention the AI can drift from. A constraint the build enforces.
What is a Polylith interface?
The only public surface of a component, exposed through a single interface namespace. In Clojure, the path is <top-namespace>.<component>.interface. All implementation details are hidden. poly check enforces this — you cannot import a component's internal namespaces from another component.
Click to reveal answer
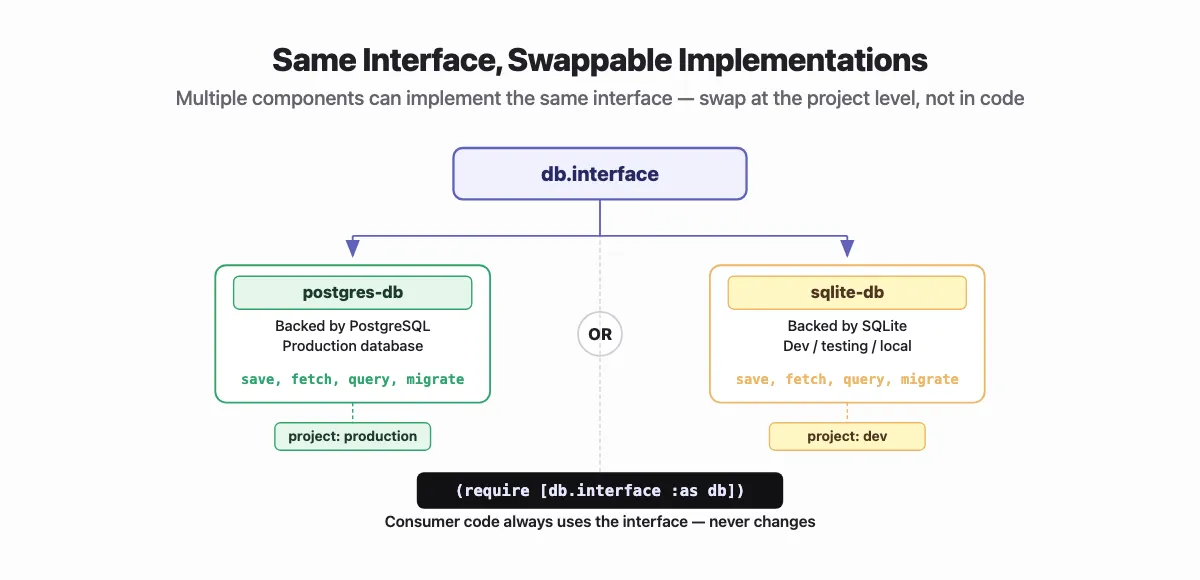
Multiple components can implement the same interface. Run poly info on any Polylith workspace and you'll see the full map — every component, every base, every interface, and which projects include which implementations. A postgres-db and sqlite-db can both expose com.acme.db.interface. Projects select which implementation to include. Consumer code never changes — it always depends on the interface, not the implementation. You swap at the project level, not the code level.
It's the Unix philosophy: small, composable pieces, enforced at the namespace level.
Polylith wasn't designed for AI. It was designed for humans. To make large Clojure codebases manageable without the operational cost of microservices. The AI advantage is accidental. Good architecture tends to reward many things at once.
Why it works for AI
One repository means one context. The AI sees everything: all components, all interfaces, all conventions, all test patterns. Ask it to add a payment handler and it already knows what the auth interface looks like, how the db component is structured, what the test conventions are. It can follow a call across the whole system.
The interface boundary matters too. Because poly check enforces it, the AI can't suggest reaching into auth.core from another component — that won't compile. It can only use what's exposed. The guessing stops.
What two things does Polylith give AI coding assistants?
Full system visibility (single repository, full context) and enforced interface contracts (poly check rejects imports of internal namespaces — not just by convention, but as a hard build check).
Click to reveal answer
workspace.edn, Polylith's root configuration file, is a machine-readable index of every component, every dependency, every project in the system. Claude Code can read it on the first prompt.
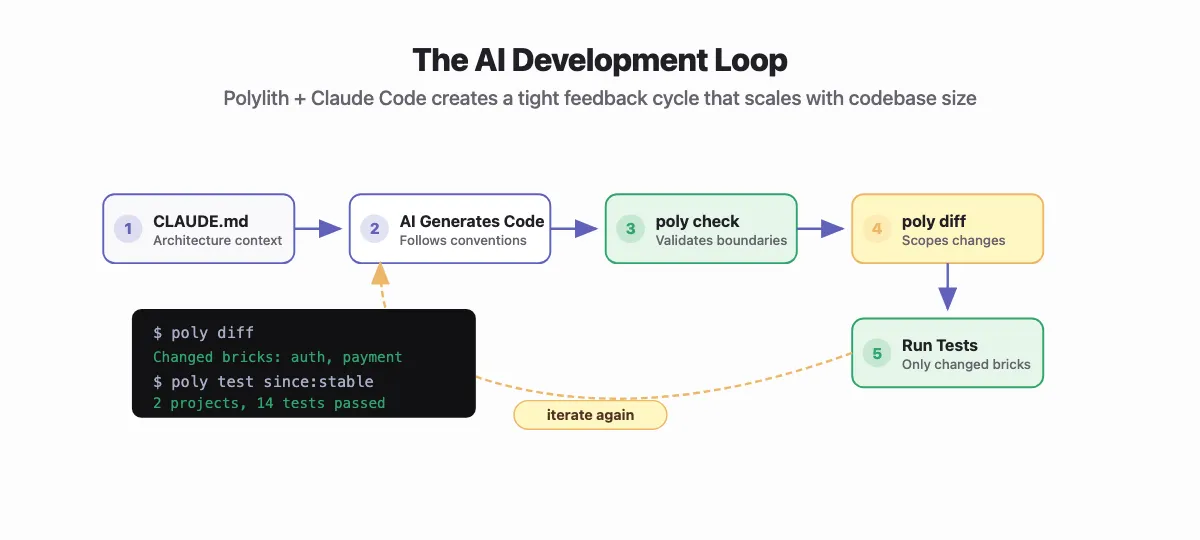
How this plays out with Claude Code
Describe your Polylith architecture once in a CLAUDE.md at the root. Something like:
## Architecture
This is a Polylith monorepo. Components live in `components/`, bases in `bases/`.
- Components expose public API only through their `interface` namespace
- Never import a component's implementation namespace directly
- Add new dependencies to the component's `deps.edn`, then run `poly check`
- Use `poly diff` to see what changed before running tests
- Namespace convention: `com.acme.<component>.<namespace>`
Claude Code reads this and carries it everywhere.
Ask it to add a feature. It already knows what components exist, what interfaces are available, and what test conventions to follow. It generates the right require:
(:require [com.acme.auth.interface :as auth]) ;; correct
;; not
(:require [com.acme.auth.core :as auth]) ;; rejected by poly check
And when it's done, poly info marks changed bricks with * in its table, so you test only what changed:
$ poly test :project since:previous-stable
2 projects, 14 tests passed
The AI makes a change. poly info scopes the feedback. The loop stays tight even as the codebase grows.
Component names are load-bearing in Polylith. You can't hide bad naming inside a utils namespace. The AI inherits that legibility and finds the right place because the names say what things do.
The skill
We packaged this as a Claude Code skill you can drop into any Polylith project.
It covers workspace structure, interface conventions, dependency rules, poly CLI commands, and naming principles — nothing project-specific. Check it into your repo as a team skill, or drop it in ~/.claude/skills/ for personal use across projects.
Install:
# Clone the skill
git clone https://github.com/vadelabs/polylith-skill
# Team-shared: checked into your project
cp -r polylith-skill/.claude/skills/polylith YOUR_PROJECT/.claude/skills/
# Personal: available across all your projects
cp -r polylith-skill/.claude/skills/polylith ~/.claude/skills/
Then in your CLAUDE.md:
Load the polylith skill when working in this repository.
Claude Code stops importing implementation namespaces, reaches for poly check after adding dependencies, and uses poly diff before running a full test suite.
Get the skill: github.com/vadelabs/polylith-skill — drop it into any Polylith project and Claude Code understands your architecture from the first prompt.
What surprised me
I expected AI output quality to improve as models improved. It does. But the ceiling is set earlier, by whether the AI can see and navigate your system.
I see teams where AI is genuinely accelerating development. I also see teams that aren't getting there. The gap isn't the model — it's whether their architecture helps the model search, find what's relevant, and build context. The teams that struggle haven't made that investment yet.
I didn't choose Polylith for AI. Nobody did. It predates these tools by years. But the properties that make it a good architecture for humans — small, bounded, named things with explicit surfaces — turn out to be exactly what AI needs too.
If you're building with Claude Code or any AI coding assistant, try the polylith-skill. Two minutes to install, and your AI stops guessing at your architecture.